1과목: 과목 구분 없음
1. CPU가 명령어를 실행할 때 필요한 피연산자를 얻기 위해 메모리에 접근하는 횟수가 가장 많은 주소지정 방식(addressing mode)은? (단, 명령어는 피연산자의 유효 주소를 얻기 위한 정보를 포함하고 있다고 가정한다)
- 직접 주소지정 방식 (direct addressing mode)
- 간접 주소지정 방식 (indirect addressing mode)
- 인덱스 주소지정 방식 (indexed addressing mode)
- 상대 주소지정 방식 (relative addressing mode)






2. 컴퓨터 시스템에서 일반적인 메모리 계층 구조를 설계하는 방식에 대한 설명으로 옳지 않은 것은?
- 상대적으로 빠른 접근 속도의 메모리를 상위 계층에 배치한다.
- 상대적으로 큰 용량의 메모리를 상위 계층에 배치한다.
- 상대적으로 단위 비트 당 가격이 비싼 메모리를 상위 계층에 배치한다.
- 하위 계층에는 하드디스크나 플래시(flash) 메모리 등 비휘발성 메모리를 주로 사용한다.
3. 클라이언트/서버 구조에 대한 설명으로 옳지 않은 것은?
- 클라이언트와 서버는 동시에 같은 물리적 컴퓨터에 위치할 수 없다.
- 클라이언트와 서버의 플랫폼과 운영체제는 서로 다를 수 있다.
- 클라이언트는 사용자에게 친숙한 인터페이스를 제공하고, 서버는 클라이언트를 위한 공유 서비스의 집합을 제공한다.
- 분산 환경에서 정보 시스템 구축의 핵심 기술로 사용되고 있다.
4. 데이터베이스 스키마(schema)에 대한 설명으로 옳지 않은 것은?
- 스키마(schema)는 데이터베이스의 논리적 정의인 데이터의 구조와 제약 조건에 대한 명세를 기술한 것이다.
- 외부 스키마(external schema)는 데이터베이스의 개별 사용자나 응용 프로그래머가 접근하는 데이터베이스를 정의한 것이다.
- 내부 스키마(internal schema)는 여러 개의 외부 스키마를 통합하는 관점에서 논리적인 데이터베이스를 기술한 것이다.
- 개념 스키마(conceptual schema)는 모든 응용 시스템들이나 사용자들이 필요로 하는 데이터를 통합한 조직 전체의 데이터 베이스를 기술한 것으로 하나의 데이터베이스 시스템에는 하나의 개념 스키마만 존재한다.
5. 다음 2진수 산술 연산의 결과와 값이 다른 것은? (단, 두 2진수는 양수이며, 연산 결과 오버플로(overflow)는 발생하지 않는다고 가정한다)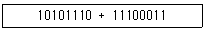
- 2진수 110010001
- 8진수 421
- 10진수 401
- 16진수 191
6. 다음 부울 함수식 F를 간략화한 결과로 옳은 것은?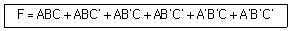
- F=A'+B
- F=A+B'
- F=A'B
- F=AB'
7. 자료 구조 중 최악의 경우를 기준으로 했을 때 탐색(search) 성능이 가장 좋은 것은?
- 정렬되지 않은 배열
- 체인법을 이용하는 해쉬 테이블
- 이진 탐색 트리
- AVL 트리
8. 다음 C 프로그램의 실행 결과로 옳은 것은?
- 11 12 13 14
- 11 22 33 44
- 22 23 24 25
- 22 33 44 55
9. 인터넷 접속 장비가 급격히 늘어남에 따라 신규로 할당할 수 있는 IP 주소의 고갈이 예상된다. 다음 중 IP 주소 고갈 문제에 대한 해결 방안과 연관이 있는 것을 모두 고른 것은?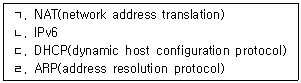
- ㄱ, ㄹ
- ㄴ, ㄷ
- ㄱ, ㄴ, ㄷ
- ㄴ, ㄷ, ㄹ
10. 프로세스들의 도착 시간과 실행 시간이 다음과 같다. CPU 스케줄링 정책으로 라운드로빈(round-robin) 알고리즘을 사용할 경우 평균 대기 시간은 얼마인가? (단, 시간 할당량은 10초이다)
- 10.8초
- 12.2초
- 13.6초
- 14.4초
11. 명령어와 데이터 스트림을 처리하기 위한 하드웨어 구조에 따른 Flynn의 분류에 대한 설명으로 옳지 않은 것은?
- SISD는 제어장치와 프로세서를 각각 하나씩 갖는 구조이며 한 번에 한 개씩의 명령어와 데이터를 처리하는 단일 프로세서 시스템이다.
- SIMD는 여러 개의 프로세서들로 구성되고 프로세서들의 동작은 모두 하나의 제어장치에 의해 제어된다.
- MISD는 여러 개의 제어장치와 프로세서를 갖는 구조로 각 프로세서들은 서로 다른 명령어들을 실행하지만 처리하는 데이터는 하나의 스트림이다.
- MIMD는 명령어가 순서대로 실행되지만 실행과정은 여러 단계로 나누어 중첩시켜 실행 속도를 높이는 방법이다.
12. 인터넷 환경에서 다른 사용자들이 송수신하는 네트워크 상의 데이터를 도청하여 패스워드나 중요한 정보를 알아내는 형태의 공격은?
- 서비스 거부(DoS : denial of service) 공격
- ICMP 스머프(smurf) 공격
- 스니핑(sniffing)
- 트로이 목마(Trojan horse)
13. 분산처리시스템에 대한 설명으로 옳지 않은 것은?
- 분산되어 있는 자원을 공유할 수 있으며 분산 처리를 통해 컴퓨팅 성능을 향상시킬 수 있다.
- 성(star)형 연결 구조의 경우 중앙 노드에 부하가 집중되어 성능이 저하되거나 중앙 노드 고장시 전체 시스템이 마비될 수 있다.
- 계층 연결 구조의 경우 인접 형제 노드간 통신은 부모 노드를 거치지 않고 이루어질 수 있다.
- 다중 접근 버스 연결 구조의 경우 한 노드의 고장이 다른 노드의 작동이나 통신에 거의 영향을 주지 않는다.
14. 모듈의 결합도(coupling)와 응집력(cohesion)에 대한 설명으로 옳은 것은?
- 결합도란 모듈 간에 상호 의존하는 정도를 의미한다.
- 결합도는 높을수록 좋고 응집력은 낮을수록 좋다.
- 여러 모듈이 공동 자료 영역을 사용하는 경우 자료 결합(data coupling)이라 한다.
- 가장 이상적인 응집은 논리적 응집(logical cohesion)이다.
15. 큐(queue) 자료구조에 대한 설명으로 옳지 않은 것은?
- 자료의 삽입과 삭제는 같은 쪽에서 이루어지는 구조다.
- 먼저 들어온 자료를 먼저 처리하기에 적합한 구조다.
- 트리(tree)의 너비 우선 탐색에 이용된다.
- 배열(array)이나 연결 리스트(linked list)를 이용해서 큐를 구현할 수 있다.
16. 운영체제의 디스크 스케줄링에 대한 설명으로 옳지 않은 것은?
- FCFS 스케줄링은 공평성이 유지되며 스케줄링 방법 중 가장 성능이 좋은 기법이다.
- SSTF 스케줄링은 디스크 요청들을 처리하기 위해서 현재 헤드 위치에서 가장 가까운 요청을 우선적으로 처리하는 기법이다.
- C-SCAN 스케줄링은 양쪽 방향으로 요청을 처리하는 SCAN 스케줄링 기법과 달리 한쪽 방향으로 헤드를 이동해 갈 때만 요청을 처리하는 기법이다.
- 섹터 큐잉(sector queuing)은 고정 헤드 장치에 사용되는 기법으로 디스크 회전 지연 시간을 고려한 기법이다.
17. 웹환경에서 사용되는 쿠키(cookie)에 대한 설명으로 옳지 않은 것은?
- 쿠키는 사용자가 웹사이트에 접속할 때 생성되는 파일이다.
- 웹사이트는 쿠키를 이용하여 웹사이트 사용자에 대한 정보를 저장할 수 있다.
- 쿠키에 저장되는 내용은 쿠키의 사용목적에 따라 결정된다.
- 쿠키는 웹사이트에서 생성되고 웹사이트에 저장되는 파일이다.
18. 컴퓨터와 네트워크 보안에 대한 설명으로 옳지 않은 것은?
- 인증(authentication)이란 호스트나 서비스가 사용자의 식별자를 검증하는 것을 의미한다.
- 기밀성(confidentiality)이란 인증된 집단만 데이터를 읽는 것이 가능한 것을 의미한다.
- 무결성(integrity)이란 모든 집단이 데이터를 수정할 수 있도록 허가한다는 것을 의미한다.
- 가용성(availability)이란 인증된 집단이 컴퓨터 시스템의 자산들을 사용할 수 있다는 것을 의미한다.
19. 뉴스, 채용정보, 블로그 같은 웹사이트들에서 자주 갱신되는 콘텐츠 정보를 웹사이트들간에 교환하기 위해 만들어진 XML(extensible markup language) 기반 형식으로 옳은 것은?
- XSS(cross site scripting)
- PICS(platform for internet content selection)
- RSS(really simple syndication)
- XHTML(extensible HTML)
20. C 프로그램에서 int 형 변수 a와 b의 값이 모두 5일 때, 다음 연산 중 결과 값이 같은 것끼리 묶은 것은?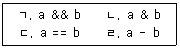
- ㄱ, ㄴ
- ㄱ, ㄷ
- ㄴ, ㄷ
- ㄴ, ㄹ
오답 노트
직접 주소지정: 메모리에 한 번 접근하여 데이터 획득
인덱스/상대 주소지정: 레지스터 값을 더해 유효 주소를 계산하므로 메모리 접근 횟수가 간접 방식보다 적음