1과목: 과목 구분 없음
1. 마이크로 연산(operation)에 대한 설명으로 옳지 않은 것은?
- 한 개의 클럭 펄스 동안 실행되는 기본 동작이다.
- 한 개의 마이크로 연산 수행시간을 마이크로 사이클 타임이라 부르며 CPU 속도를 나타내는 척도로 사용된다.
- 하나의 명령어는 항상 하나의 마이크로 연산이 동작되어 실행된다.
- 시프트(shift), 로드(load) 등이 있다.






2. 주기억장치에서 사용가능한 부분은 다음과 같다. M1은 16KB (kilobyte), M2는 14KB, M3는 5KB, M4는 30KB이며 주기억장치의 시작 부분부터 M1, M2, M3, M4 순서가 유지되고 있다. 이때 13KB를 요구하는 작업이 최초적합(First Fit) 방법, 최적적합(Best Fit) 방법, 최악적합(Worst Fit) 방법으로 주기억장치에 각각 배치될 때 결과로 옳은 것은? 단, 배열순서는 왼쪽에서 첫 번째가 최초적합 결과이며 두 번째가 최적적합 결과 그리고 세 번째가 최악적합 결과를 의미한다.
- M1, M2, M3
- M1, M2, M4
- M2, M1, M4
- M4, M2, M3
3. 웹 애플리케이션을 개발하기 위한 스크립트 언어 중 성격이 다른 것은?
- Javascript
- JSP
- ASP
- PHP
4. 해시(hash) 탐색에서 제산법(division)은 키(key) 값을 배열(array)의 크기로 나누어 그 나머지 값을 해시 값으로 사용하는 방법이다. 다음 데이터의 해시 값을 제산법으로 구하여 11개의 원소를 갖는 배열에 저장하려고 한다. 해시 값의 충돌(collision)이 발생하는 데이터를 열거해 놓은 것은?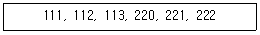
- 111, 112
- 112, 222
- 113, 221
- 220, 222
5. 회사에서 211.168.83.0(클래스 C)의 네트워크를 사용하고 있다. 내부적으로 5개의 서브넷을 사용하기 위해 서브넷 마스크를 255.255.255.224로 설정하였다. 이때 211.168.83.34가 속한 서브넷의 브로드캐스트 주소는 어느 것인가?
- 211.168.83.15
- 211.168.83.47
- 211.168.83.63
- 211.168.83.255
6. 데이터베이스 설계 시에 양질의 데이터베이스를 구축하기 위하여 데이터베이스 릴레이션을 정규화한다. 이때 고려해야 할 사항과 가장 관련이 없는 것은?
- 원하지 않는 데이터의 중복을 제거한다.
- 원하지 않는 데이터의 종속을 제거한다.
- 한 릴레이션 내의 속성들 간의 관계를 고려한다.
- 한 릴레이션 내의 투플들 간의 관계를 고려한다.
7. Windows XP에서 프린터 설정에 관한 설명으로 옳지 않은 것은?
- 기본 프린터는 오직 1대만 설정할 수 있다.
- 네트워크 프린터는 기본 프린터로 설정할 수 없다.
- 한 대의 프린터를 여러 대의 컴퓨터에서 네트워크로 공유 가능하다.
- [네트워크 설정 마법사]를 통해 파일 및 프린터도 공유할 수 있다.
8. 운영체제는 일괄처리(batch), 대화식(interactive), 실시간(real-time)시스템 그리고 일괄처리와 대화식이 결합된 혼합(hybrid) 시스템 등으로 분류될 수 있다. 이와 같은 분류 근거로 가장 알맞은 것은?
- 고급 프로그래밍 언어의 사용 여부
- 응답 시간과 데이터 입력 방식
- 버퍼링(buffering) 기능 수행 여부
- 데이터 보호의 필요성 여부
9. 다음 그래프를 너비 우선 탐색(Breadth First Search BFS), 깊이 우선 탐색(Depth First Search DFS) 방법으로 방문할 때 각 정점을 방문하는 순서로 옳은 것은? 단, 둘 이상의 정점을 선택할 수 있을 때는 알파벳 순서로 방문한다. (순서대로 BFS, DFS)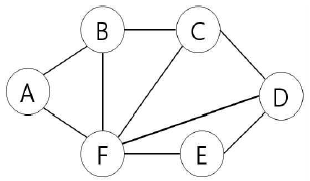
- A-B-F-C-E-D, A-B-C-D-E-F
- A-B-C-D-E-F, A-B-F-C-E-D
- A-B-F-C-D-E, A-B-C-D-E-F
- A-B-C-D-E-F, A-B-C-D-F-E

10. SQL에서는 데이터베이스 검색의 성능 및 편의 향상을 위하여 내장함수를 제공한다. 다음 중 SQL의 내장 집계함수(aggregate function)가 아닌 것은?
- COUNT
- SUM
- TOTAL
- MAX
11. 다음의 Java 프로그램에서 사용되지 않은 기법은?
- 캡슐화(Encapsulation)
- 상속(Inheritance)
- 오버라이딩(Overriding)
- 오버로딩(Overloading)
 를 분석하면 다음과 같습니다.
를 분석하면 다음과 같습니다.
12. 다음에서 ㉠과 ㉡에 들어갈 내용이 올바르게 짝지어진 것은? (순서대로 ㉠, ㉡)
- 인출, MAR ← PC
- 인출, MAR ← MBR(AD)
- 실행, MAR ← PC
- 실행, MAR ← MBR(AD)
13. MS Excel의 워크시트에서 사원별 수주량과 판매금액, 그리고 수주량과 판매금액의 합계가 입력되어 있다. 이때 C열에는 전체 수주량 대비 각 사원 수주량의 비율을, E열에는 전체 판매금액 대비 각 사원 판매금액의 비율을 보이고자 한다. 이를 위해 C2셀에 수식을 입력한 다음에 이를 C열과 E열의 나머지 셀에 복사하여 사용하고자 한다. C2셀에 입력할 내용으로 옳은 것은?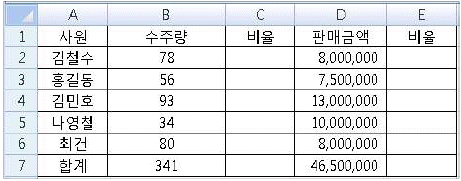
- =B2/B7*100
- =$B$2/B7*100
- =B2/$B$7*100
- =B2/B$7*100
14. 후위(postfix) 형식으로 표기된 다음 수식을 스택(stack)으로 처리하는 경우에, 스택의 탑(TOP) 원소의 값을 올바르게 나열한 것은? 단, 연산자(operator)는 한 자리의 숫자로 구성되는 두 개의 피연산자(operand)를 필요로 하는 이진(binary) 연산자이다.
- 4, 5, 2, 3, 6, -1, 3
- 4, 5, 9, 2, 3, 6, -3
- 4, 5, 9, 2, 18, 3, 16
- 4, 5, 9, 2, 3, 6, 3

15. <보기>는 자료의 표현과 관련된 설명이다. 옳은 것을 모두 고른 것은?
- ㄱ, ㄹ
- ㄴ, ㄷ
- ㄱ, ㄴ, ㄷ
- ㄱ, ㄴ, ㄹ
16. 웹 개발 기법의 하나인 Ajax(Asynchronous Javascript and XML)에 대한 설명으로 옳지 않은 것은?
- 대화식 웹 애플리케이션을 개발하기 위해 사용된다.
- 기술의 묶음이라기보다는 웹 개발을 위한 특정한 기술을 의미한다.
- 서버 처리를 기다리지 않고 비동기 요청이 가능하다.
- Prototype, JQuery, Google Web Toolkit은 대표적인 Ajax 프레임워크이다.
17. C 프로그램의 실행 결과로 옳은 것은?
- i = 0.0 j = 0 k = 3 m = 003
- i = 0.3 j = 0 k = 3 m = 000
- i = 0.0 j = 1 k = 1 m = 001
- i = 0.3 j = 1 k = 1 m = 001
18. 화소(pixel)당 24비트 컬러를 사용하고 해상도가 352×240 화소인 TV영상프레임(frame)을 초당 30개 전송할 때 필요한 통신 대역폭으로 가장 가까운 것은?
- 약 10Mbps
- 약 20Mbps
- 약 30Mbps
- 약 60Mbps
19. 데이터베이스 관리시스템(DBMS)에서 질의 처리를 빠르게 수행하기 위해 질의를 최적화한다. 질의 최적화 시에 사용하는 경험적 규칙으로서 알맞지 않은 것은?
- 추출(project) 연산은 일찍 수행한다.
- 조인(join) 연산은 가능한 한 일찍 수행한다.
- 선택(select) 연산은 가능한 한 일찍 수행한다.
- 중간 결과를 적게 산출하면서 빠른 시간에 결과를 줄 수 있어야 한다.
20. 컴퓨터 시스템의 성능을 측정하는 척도에 대한 설명으로 알맞지 않은 것은?
- 처리량(throughput)은 보통 안정된 상태에서 측정되며 하루에 처리되는 작업의 개수 또는 시간당 처리되는 온라인 처리의 개수 등으로 측정된다.
- 병목(bottleneck) 현상은 시스템 자원이 용량(capacity) 또는 처리량에 있어서 최대 한계에 도달할 때 발생될 수 있다.
- 응답 시간(response time)은 주어진 작업의 수행을 위해 시스템에 도착한 시점부터 완료되어 그 작업의 출력이 사용자에게 제출되는 시점까지의 시간으로 정의된다.
- 자원 이용도(utilization)는 일반적으로 전체 시간에 대해 주어진 자원이 실제로 사용되는 시간의 백분율로 나타낸다.