1과목: 과목 구분 없음
1. 관계데이터베이스 관련 다음 설명에서 ㉠~㉣에 들어갈 용어를 바르게 짝지은 것은?
- ㉠참조 ㉡고립성 ㉢변경 ㉣외래키
- ㉠개체 ㉡고립성 ㉢참조 ㉣기본키
- ㉠참조 ㉡도메인 ㉢참조 ㉣외래키
- ㉠개체 ㉡도메인 ㉢변경 ㉣기본키

 문맥상 ㉠은 참조 무결성, ㉡은 속성이 가질 수 있는 값의 범위인 도메인, ㉢은 참조 무결성 유지, ㉣은 다른 릴레이션의 기본키를 참조하는 외래키가 들어가는 것이 적절합니다.
문맥상 ㉠은 참조 무결성, ㉡은 속성이 가질 수 있는 값의 범위인 도메인, ㉢은 참조 무결성 유지, ㉣은 다른 릴레이션의 기본키를 참조하는 외래키가 들어가는 것이 적절합니다.




2. 다음 워크시트에서 [D1] 셀에 =$A$1+$B2를 입력한 후 [D1] 셀을 복사하여 [D5] 셀에 붙여넣기 했을 때 [D5] 셀에 표시될 수 있는 결과로 옳은 것은?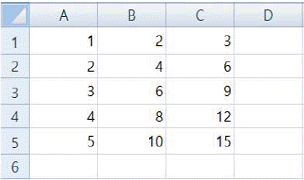
- 1
- 7
- 9
- 15
3. 관계데이터베이스의 인덱스(index)에 대한 설명으로 옳은 것의 총 개수는?
- 1개
- 2개
- 3개
- 4개
4. 트랜잭션(transaction)의 복구(recovery) 진행 시 복구대상을 제외, 재실행(Redo), 실행취소(Undo) 할 것으로 구분하였을 때 옳은 것은?
- ①
- ②
- ③
- ④
5. 다음 워크시트에서 수식 =VLOOKUP(LARGE(C4:C11,3), C4:F11, 4, 0)에 의해 표시될 수 있는 결과로 옳은 것은?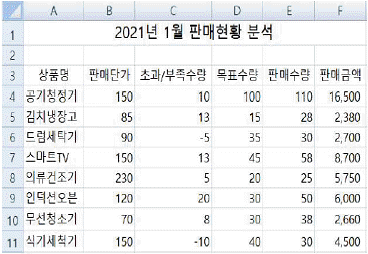
- 58
- 2,380
- 8,700
- 16,500
6. UML의 클래스 다이어그램에서 클래스 사이의 관계에 대한 설명으로 옳지 않은 것은?
- 일반화(generalization) 관계는 일반화한 부모 클래스와 실체화한 자식 클래스 간의 상속 관계를 나타낸다.
- 연관(association) 관계에서 다중성(multiplicity)은 관계 사이에 개입하는 클래스의 인스턴스 개수를 의미한다.
- 의존(dependency) 관계는 한 클래스가 다른 클래스를 참조하는 것으로 지역변수, 매개변수 등을 일시적으로 사용하는 관계이다.
- 집합(aggregation) 관계는 강한 전체와 부분의 클래스 관계이므로 전체 객체가 소멸되면 부분 객체도 소멸된다.
7. 다음에서 설명하는 소프트웨어 아키텍처의 유형으로 옳은 것은?
- 클라이언트-서버(client-server) 아키텍처
- 브로커(broker) 아키텍처
- MVC(Model-View-Controller) 아키텍처
- 계층형(layered) 아키텍처
8. 다음 C 프로그램의 실행 결과로 옳은 것은?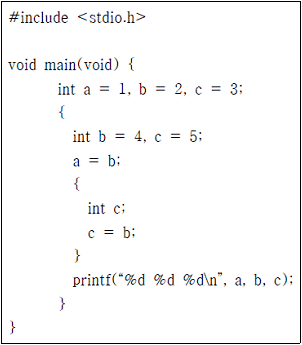
- 1 2 3
- 1 4 5
- 4 2 3
- 4 4 5
9. 클라우드 서버에 저장된 데이터 용량이 1024PB(Peta Byte)일 때 이 데이터와 동일한 크기의 저장 용량으로 옳지 않은 것은? (단, 1KB는 1024Byte)
- 1024-1ZB(Zetta Byte)
- 10242TB(Tera Byte)
- 1024-3YB(Yotta Byte)
- 10244MB(Mega Byte)
10. 유비쿼터스 컴퓨팅 기술에 대한 설명으로 옳지 않은 것은?
- 노매딕 컴퓨팅(nomadic computing)은 사용자가 모든 장소에서 사용자 인증 없이 다양한 정보기기로 동일한 데이터에 접근하는 기술이다.
- 엑조틱 컴퓨팅(exotic computing)은 스스로 생각하여 현실세계와 가상세계를 연계하는 컴퓨팅을 실현해 주는 기술이다.
- 감지 컴퓨팅(sentient computing)은 센서가 사용자의 상황을 인식하여 사용자가 필요한 정보를 제공해 주는 기술이다.
- 임베디드 컴퓨팅(embedded computing)은 사물에 마이크로칩을 장착하여 서비스 기능을 내장하는 컴퓨팅 기술이다.
11. 하나의 컴퓨터 시스템에서 여러 개의 어플리케이션(application)들이 함께 주기억장치에 적재되어 하나의 CPU 자원을 번갈아 사용하는 형태로 수행되게 하는 기법으로 옳은 것은?
- 다중프로그래밍(multi-programming)
- 다중프로세싱(multi-processing)
- 병렬처리(parallel processing)
- 분산처리(distributed processing)
12. 주기억장치와 CPU 캐시 기억장치만으로 구성된 시스템에서 다음과 같이 기억장치 접근 시간이 주어질 때 이 시스템의 캐시 적중률(hit ratio)로 옳은 것은?
- 80%
- 85%
- 90%
- 95%
13. 컴퓨터 시스템의 주기억장치 및 보조기억장치에 대한 설명으로 옳지 않은 것은?
- RAM은 휘발성(volatile) 기억장치이며 HDD 및 SSD는 비휘발성(non-volatile) 기억장치이다.
- RAM의 경우, HDD나 SSD 등의 보조기억장치에 비해 상대적으로 접근 속도가 빠르다.
- SSD에서는 일반적으로 특정 위치의 데이터를 읽는 데 소요되는 시간이 같은 위치에 데이터를 쓰는 데 소요되는 시간보다 더 오래 걸린다.
- SSD의 경우, 일반적으로 HDD보다 가볍고 접근 속도가 빠르며 전력 소모가 적다.
14. 다음 표에서 보인 4개의 프로세스들을 시간 할당량(time quantum)이 5인 라운드로빈(round-robin) 스케줄링 기법으로 실행시켰을 때 평균 반환 시간으로 옳은 것은?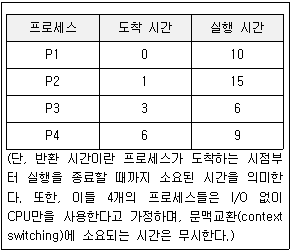
- 24.0
- 29.0
- 29.75
- 30.25
15. LRU(Least Recently Used) 교체 기법을 사용하는 요구 페이징(demand paging) 시스템에서 3개의 페이지 프레임(page frame)을 할당받은 프로세스가 다음과 같은 순서로 페이지에 접근했을 때 발생하는 페이지 부재(page fault) 횟수로 옳은 것은? (단, 할당된 페이지 프레임들은 초기에 모두 비어 있다고 가정한다.)
- 7번
- 10번
- 14번
- 15번
16. 인터넷에서 사용하는 IPv6에 대한 설명으로 옳지 않은 것은?
- 패킷 헤더의 체크섬(checksum)을 통해 데이터 무결성 검증 기능을 지원한다.
- QoS(Quality of Service) 보장을 위해 흐름 레이블링(flow labeling) 기능을 지원한다.
- IPv6의 주소 체계는 16비트씩 8개 부분, 총 128비트로 구성되어 있다.
- IPv6 주소 표현에서 연속된 0에 대한 생략을 위한 :: 표기는 1번만 가능하다.
17. 다음 정수를 왼쪽부터 순서대로 삽입하여 이진 탐색 트리(binary search tree)를 구성했을 때 단말 노드(leaf node)를 모두 나열한 것은?
- 16, 49, 51, 57, 85
- 16, 49, 57, 68, 85
- 49, 51, 57, 68, 85
- 49, 57, 68, 75, 85
 을 순서대로 삽입하면 다음과 같이 구성됩니다.
을 순서대로 삽입하면 다음과 같이 구성됩니다.
18. 다음 과정을 통해 수행되는 정렬 알고리즘의 특징으로 옳지 않은 것은?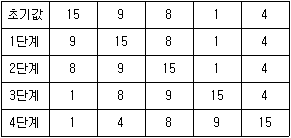
- 최악의 경우에 시간 복잡도는 O(n2)이다.
- 원소 수가 적거나 거의 정렬된 경우에 효과적이다.
- 선택정렬(selection sort)에 비해 비교연산 횟수가 같거나 적다.
- 정렬 대상의 크기만큼 추가 공간이 필요하다.
19. SET(Secure Electronic Transaction)에 대한 설명으로 옳지 않은 것은?
- 프라이버시 보호를 위해 이중서명 프로토콜을 사용한다.
- 카드 소지자는 전자 지갑 소프트웨어가 필요하다.
- 인증기관(Certification Authority)이 필요하다.
- SSL(Secure Socket Layer)에 비해 고속으로 동작한다.
20. 「개인정보 보호법」의 개인정보 보호 원칙으로 옳은 것의 총 개수는?
- 1개
- 2개
- 3개
- 4개