1과목: 과목 구분 없음
1. 인터프리터(Interpreter) 방식의 언어로 옳지 않은 것은?
- JavaScript
- C
- Basic
- LISP






2. CPU 스케줄링 기법 중 라운드 로빈(Round Robin) 방식에 대한 설명으로 옳지 않은 것은?
- 선점 스케줄링 기법이다.
- 여러 프로세스에 일정한 시간을 할당한다.
- 시간할당량이 작으면 문맥 교환수와 오버헤드가 증가한다.
- FIFO(First-In-First-Out) 방식 대비 높은 처리량을 제공한다.
3. 프로세서의 수를 늘려도 속도를 개선하는 데 한계가 있다는 주장으로서, 병렬처리 프로세서의 성능 향상의 한계를 지적한 법칙은?
- 무어의 법칙(Moore’s Law)
- 암달의 법칙(Amdahl’s Law)
- 구스타프슨의 법칙(Gustafson’s Law)
- 폰노이만 아키텍처(von Neumann Architecture)
4. 교착상태 발생의 조건에 대한 설명으로 옳지 않은 것은?
- 상호 배제 조건:최소한 하나의 자원이 비공유 모드로 점유되며, 비공유 모드에서는 한 번에 한 프로세스만 해당 자원을 사용할 수 있다.
- 점유와 대기 조건:프로세스는 최소한 하나의 자원을 점유한 채, 현재 다른 프로세스에 의해 점유된 자원을 추가로 얻기 위해 반드시 대기해야 한다.
- 비선점 조건:프로세스에 할당된 자원은 사용이 끝날 때까지 다른 프로세스가 강제로 빼앗을 수 없다.
- 순환 대기 조건:대기 체인 내 프로세스들의 집합에서 이전 프로세스는 다음 프로세스가 점유한 자원을 대기하고, 마지막 프로세스는 자원을 대기하지 않아야 한다.
5. CPU(중앙처리장치)의 성능 향상을 위해 한 명령어 사이클 동안 여러 개의 명령어를 동시에 처리할 수 있도록 설계한 CPU구조는?
- 슈퍼스칼라(Superscalar)
- 분기 예측(Branch Prediction)
- VLIW(Very Long Instruction Word)
- SIMD(Single Instruction Multiple Data)
6. 캐시기억장치 접근시간이 20ns, 주기억장치 접근시간이 150ns, 캐시기억장치 적중률이 80%인 경우에 평균 기억장치 접근시간은? (단, 기억장치는 캐시와 주기억장치로만 구성된다)
- 32ns
- 46ns
- 124ns
- 170ns
7. 아날로그 컴퓨터에 대한 설명으로 옳지 않은 것은?
- 입력형식은 부호, 코드화된 숫자, 문자, 기호이다.
- 출력형식은 곡선, 그래프 등이다.
- 미적분 연산방식을 가지며, 정보처리속도가 빠르다.
- 증폭회로 등으로 회로 구성을 한다.
8. RAID(Redundant Array of Inexpensive Disks)에 대한 설명으로 옳지 않은 것은?
- RAID-0은 디스크 스트라이핑(Disk Striping) 방식으로 중복 저장과 오류 검출 및 교정이 없는 방식이다.
- RAID-1은 디스크 미러링(Disk Mirroring) 방식으로 높은 신뢰도를 갖는다.
- RAID-4는 데이터를 비트(bit) 단위로 여러 디스크에 분할하여 저장하는 방식이며, 별도의 패리티(parity) 디스크를 사용한다.
- RAID-5는 별도의 패리티 디스크 대신 모든 디스크에 패리티 정보를 나누어 기록하는 방식이다.
9. 다음 재귀 함수를 동일한 기능의 반복 함수로 바꿀 때, ㉠과 ㉡에 들어갈 내용을 바르게 연결한 것은? (순서대로 ㉠, ㉡)
- n < 0, f = f * n--;
- n < 0, f = f * n++;
- n > 0, f = f * n--;
- n > 0, f = f * n++;
10. 데이터의 종류 및 처리에 대한 설명으로 옳지 않은 것은?
- 크롤링(Crawling)을 통해 얻은 웹문서의 텍스트 데이터는 대표적인 정형 데이터(Structured Data)이다.
- XML로 작성된 IoT 센서 데이터는 반정형 데이터(Semi-structured Data)로 분류할 수 있다.
- 반정형 데이터는 데이터 구조에 대한 메타 데이터(Meta-data)를 포함한다.
- NoSQL과 Hadoop은 대규모 비정형 데이터(Unstructured Data) 처리에 적합하다.
11. 페이지 부재율(Page Fault Ratio)과 스래싱(Trashing)에 대한 설명으로 옳은 것은?
- 페이지 부재율이 크면 스래싱이 적게 일어난다.
- 페이지 부재율과 스래싱은 전혀 관계가 없다.
- 스래싱이 많이 발생하면 페이지 부재율이 감소한다.
- 다중 프로그램의 정도가 높을수록 스래싱이 증가한다.
12. 전자상거래 관련 기술 중 고객의 요구에 맞춰 자재조달에서부터 생산, 판매, 유통에 이르기까지 공급사슬 전체의 기능통합과 최적화를 지향하는 정보시스템은?
- ERP(Enterprise Resource Planning)
- EDI(Electronic Data Interchange)
- SCM(Supply Chain Management)
- KMS(Knowledge Management System)
13. 프로토콜과 이에 대응하는 TCP/IP 프로토콜 계층 사이의 연결이 옳지 않은 것은?
- HTTP-응용 계층
- SMTP-데이터링크 계층
- IP-네트워크 계층
- UDP-전송 계층
14. 관계 데이터베이스 스키마 STUDENT(SNO, NAME, AGE )에 대하여 다음과 같은 SQL 질의 문장을 사용한다고 할 때, 이 SQL 문장과 동일한 의미의 관계대수식은? (단, STUDENT 스키마에서 밑줄 친 속성은 기본키 속성을, 관계대수식에서 사용하는 관계대수 연산자 기호 π는 프로젝트 연산자를, 는 셀렉트 연산자를 나타낸다)
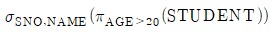
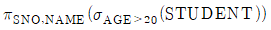
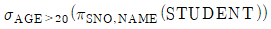
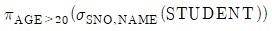
15. 두 프로토콜 개체 사이에서 흐름제어와 오류제어 및 메시지 전달 등의 기능을 수행하며, 연결성과 비연결성의 두 가지 운용모드를 제공하는 OSI 참조 모델 계층은?
- 데이터링크 계층(Datalink Layer)
- 네트워크 계층(Network Layer)
- 전송 계층(Transport Layer)
- 응용 계층(Application Layer)
16. 소프트웨어 개발 언어에 대한 설명으로 옳지 않은 것은?
- C#은 마이크로소프트 닷넷 프레임워크를 지원하는 객체지향 언어이다.
- Python은 인터프리터 방식의 객체지향 언어로서 실행시점에 데이터 타입을 결정하는 동적 타이핑 기능을 갖는다.
- Kotlin은 그래픽 요소를 강화한 게임 개발 전용 언어이다.
- Java는 컴파일된 프로그램이 JVM상에서 인터프리터 방식으로 실행되는 플랫폼 독립적 프로그래밍 언어이다.
17. 소프트웨어 시스템은 기능 관점, 동적 관점 및 정보 관점으로 분류할 수 있다. 동적 관점에서 시스템을 기술할 때 사용할 수 있는 도구로 옳지 않은 것은?
- 사건 추적도(Event Trace Diagram)
- 자료 흐름도(Data Flow Diagram)
- 상태 변화도(State Transition Diagram)
- 페트리넷(Petri Net)
18. 다음에서 설명하는 네트워크 데이터 오류 검출 방법은?
- 수직 중복 검사(Vertical Redundancy Check)
- 세로 중복 검사(Longitudinal Redundancy Check)
- 순환 중복 검사(Cyclic Redundancy Check)
- 체크섬(Checksum)
19. 다음 이진검색트리에서 28을 삭제한 후, 28의 오른쪽 서브트리에 있는 가장 작은 원소로 28을 대치하여 만들어지는 이진검색트리에서 41의 왼쪽 자식 노드는?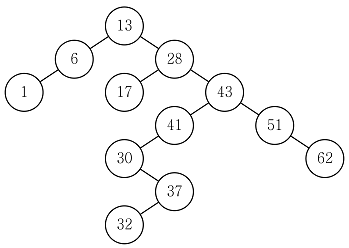
- 13
- 17
- 32
- 37
20. 다음은 리눅스 환경에서 fork() 시스템 호출을 이용하여 자식 프로세스를 생성하는 C 프로그램이다. 출력 결과로 옳은 것은? (단, “pid = fork();” 문장의 수행 결과 자식 프로세스의 생성을 성공하였다고 가정한다)
- b=120, a=6
- c=16, b=120
- b=120, c=16
- a=6, c=16