1과목: 과목 구분 없음
1. 시스템 소프트웨어에 포함되지 않는 것은?
- 스프레드시트(spreadsheet)
- 로더(loader)
- 링커(linker)
- 운영체제(operating system)






2. OSI 7계층 중 브리지(bridge)가 복수의 LAN을 결합하기 위해 동작하는 계층은?
- 물리 계층
- 데이터 링크 계층
- 네트워크 계층
- 전송 계층
3. 데이터베이스 설계 과정에서 목표 DBMS의 구현 데이터 모델로 표현된 데이터베이스 스키마가 도출되는 단계는?
- 요구사항 분석 단계
- 개념적 설계 단계
- 논리적 설계 단계
- 물리적 설계 단계
4. 객체지향 프로그래밍의 특징 중 상속 관계에서 상위 클래스에 정의된 메소드(method) 호출에 대해 각 하위 클래스가 가지고 있는 고유한 방법으로 응답할 수 있도록 유연성을 제공하는 것은?
- 재사용성(reusability)
- 추상화(abstraction)
- 다형성(polymorphism)
- 캡슐화(encapsulation)
5. 다음은 캐시 기억장치를 사상(mapping) 방식 기준으로 분류한 것이다. 캐시 블록은 4개 이상이고 사상 방식을 제외한 모든 조건이 동일하다고 가정할 때, 평균적으로 캐시 적중률(hit ratio)이 높은 것에서 낮은 것 순으로 바르게 나열한 것은?
- ㄱ-ㄴ-ㄷ
- ㄴ-ㄷ-ㄱ
- ㄷ-ㄱ-ㄴ
- ㄱ-ㄷ-ㄴ
6. 다음 논리회로의 부울식으로 옳은 것은?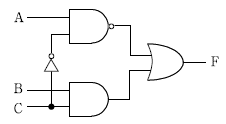
- F = AC' + BC
- F(A, B, C) = Σm(0, 1, 2, 3, 6, 7)
- F = (AC')'
- F = (A' + B' + C)(A+ B' + C')
7. 소프트웨어 개발 프로세스 모델 중 하나인 나선형 모델(spiral model)에 대한 설명으로 옳지 않은 것은?
- 폭포수(waterfall) 모델과 원형(prototype) 모델의 장점을 결합한 모델이다.
- 점증적으로 개발을 진행하여 소프트웨어 품질을 지속적으로 개선할 수 있다.
- 위험을 분석하고 최소화하기 위한 단계가 포함되어 있다.
- 관리가 복잡하여 대규모 시스템의 소프트웨어 개발에는 적합하지 않다.
8. 다음 표는 단일 CPU에 진입한 프로세스의 도착 시간과 처리하는 데 필요한 실행 시간을 나타낸 것이다. 프로세스 간 문맥 교환에 따른 오버헤드는 무시한다고 할 때, SRT(Shortest Remaining Time) 스케줄링 알고리즘을 사용한 경우 네 프로세스의 평균 반환시간(turnaround time)은?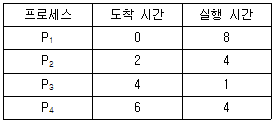
- 4.25
- 7
- 8.75
- 10
9. 이더넷(Ethernet)의 매체 접근 제어(MAC) 방식인 CSMA/CD에 대한 설명으로 옳지 않은 것은?
- CSMA/CD 방식은 CSMA 방식에 충돌 검출 기법을 추가한 것으로 IEEE 802.11b의 MAC 방식으로 사용된다.
- 충돌 검출을 위해 전송 프레임의 길이를 일정 크기 이상으로 유지해야 한다.
- 전송 도중 충돌이 발생하면 임의의 시간 동안 대기하기 때문에 지연시간을 예측하기 어렵다.
- 여러 스테이션으로부터의 전송 요구량이 증가하면 회선의 유효 전송률은 단일 스테이션에서 전송할 때 얻을 수 있는 유효 전송률보다 낮아지게 된다.
10. 다음은 C언어로 내림차순 버블정렬 알고리즘을 구현한 함수이다. ㉠에 들어갈 if문의 조건으로 올바른 것은? (단, size는 1차원 배열인 value의 크기이다)
- value[x] > value[y+1]
- value[x] < value[y+1]
- value[y] > value[y+1]
- value[y] < value[y+1]
11. 객체지향 기법을 지원하지 않는 프로그래밍 언어는?
- LISP
- Java
- Python
- C#
12. 관계형 모델(relational model)의 릴레이션(relation)에 대한 설명으로 옳지 않은 것은?
- 릴레이션의 한 행(row)을 투플(tuple)이라고 한다.
- 속성(attribute)은 릴레이션의 열(column)을 의미한다.
- 한 릴레이션에 존재하는 모든 투플들은 상이해야 한다.
- 한 릴레이션의 속성들은 고정된 순서를 갖는다.
13. 컴퓨터 버스에 대한 설명으로 옳지 않은 것은?
- 주소 정보를 전달하는 주소 버스(address bus), 데이터 전송을 위한 데이터 버스(data bus), 그리고 명령어 전달을 위한 명령어 버스(instruction bus)로 구성된다.
- 3-상태(3-state) 버퍼를 이용하면 데이터를 송신하고 있지 않는 장치의 출력이 버스에 연결된 다른 장치와 간섭하지 않도록 분리시킬 수 있다.
- 특정 장치를 이용하면 버스를 통해서 입출력 장치와 주기억 장치 간 데이터가 CPU를 거치지 않고 전송될 수 있다.
- 다양한 장치를 연결하기 위한 별도의 버스가 추가적으로 존재할 수 있다.
14. 다음 이진 트리(binary tree)의 노드들을 후위 순회(post-order traversal)한 경로를 나타낸 것은?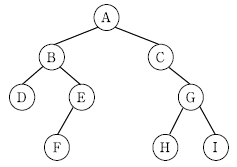
- F→H→I→D→E→G→B→C→A
- D→F→E→B→H→I→G→C→A
- D→B→F→E→A→C→H→G→I
- I→H→G→C→F→E→D→B→A
15. 프로토콜에 대한 설명으로 옳지 않은 것은?
- ARP는 데이터 링크 계층의 프로토콜로 MAC 주소에 대해 해당 IP 주소를 반환해 준다.
- UDP를 사용하면 일부 데이터의 손실이 발생할 수 있지만 TCP에 비해 전송 오버헤드가 적다.
- MIME는 텍스트, 이미지, 오디오, 비디오 등의 멀티미디어 전자우편을 위한 규약이다.
- DHCP는 한정된 개수의 IP 주소를 여러 사용자가 공유할 수 있도록 동적으로 가용한 주소를 호스트에 할당해준다.
16. 비결정적 유한 오토마타(non-deterministic finite automata)에 대한 설명으로 옳지 않은 것은?
- 한 상태에서 전이 시 다음 상태를 선택할 수 있다.
- 입력 심볼을 읽지 않고도 상태 전이를 할 수 있다.
- 어떤 비결정적 유한 오토마타라도 같은 언어를 인식하는 결정적 유한 오토마타(deterministic finite automata)로 변환이 가능하다.
- 모든 문맥 자유 언어(context-free language)를 인식한다.
17. 클라우드 컴퓨팅 서비스 모델과 이에 대한 설명이 바르게 짝지어진 것은? (순서대로 IaaS, PaaS, SaaS)
- ㄷ, ㄴ, ㄱ
- ㄴ, ㄱ, ㄷ
- ㄷ, ㄱ, ㄴ
- ㄱ, ㄷ, ㄴ
18. 다음 C 언어로 작성된 프로그램의 실행 결과에서 세 번째 줄에 출력되는 것은?
- func(3) : 6
- func(2) : 2
- func(1) : 1
- func(0) : 0
19. 서브넷 마스크(subnet mask)를 255.255.255.224로 하여 한 개의 C클래스 주소 영역을 동일한 크기의 8개 하위 네트워크로 나누었다. 분할된 네트워크에서 브로드캐스트를 위한 IP 주소의 오른쪽 8비트에 해당하는 값으로 옳은 것은?
- 0
- 64
- 159
- 207
20. 연결리스트(linked list)의 ‘preNode’ 노드와 그 다음 노드 사이에 새로운 ‘newNode’ 노드를 삽입하기 위해 빈 칸 ㉠에 들어갈 명령문으로 옳은 것은?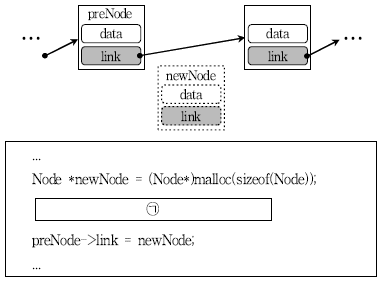
- newNode->link = preNode;
- newNode->link = preNode->link;
- newNode->link->link = preNode;
- newNode = preNode->link;