1과목: 과목 구분 없음
1. TCP(Transmission Control Protocol)와 IP(Internet Protocol)에 대한 설명으로 옳지 않은 것은?
- TCP는 호스트 사이에 신뢰성 있는 스트림(stream) 전송 서비스를 제공한다.
- IP는 수신 측 IP 주소를 바탕으로 라우팅 테이블을 갱신한다.
- TCP는 연결 지향형 프로토콜로서 실제 데이터를 전송하기 전에 연결을 설정한다.
- IP는 신뢰성을 보장하지 않는 비연결 지향형 프로토콜이다.






2. IPv4 주소를 클래스별로 분류했을 때, C 클래스에 해당하는 것은?
- 12.34.56.78
- 111.11.11.11
- 123.12.31.12
- 222.22.22.22
3. 운영체제의 스케줄링 기법에 대한 설명으로 옳지 않은 것은?
- FCFS(First-Come-First-Served) 스케줄링은 비선점(nonpreemptive)방식으로 실행 중인 프로세스가 종료하면 준비큐에서 가장 오래 대기한 프로세스를 다음 실행 프로세스로 선정한다.
- RR(Round-Robin) 스케줄링은 선점(preemptive) 방식으로 프로세스를 정해진 시간 할당량만큼 실행 후 종료하지 못하면 준비 큐로 이동시킨다.
- 비선점 SJF(Shortest-Job-First) 스케줄링은 준비 큐에서 예상 전체 실행시간이 가장 짧은 프로세스를 다음 실행프로세스로 선정한다.
- 선점 SJF 스케줄링은 SRTF(Shortest-Remaining-Time-First)스케줄링이라고 불리며 비선점 SJF 스케줄링에서 발생할 수 있는 기아상태(starvation) 문제를 해결한다.
4. 가상 객체와 실세계를 접목하여 현실감 있는 정보를 제공하는 기술은?
- 지리정보 시스템(geographical information system)
- 증강현실(augmented reality)
- 생체인식(biometrics)
- 사물인터넷(Internet of Things)
5. 10진수 -11을 5비트 2진수로 표현한 것은? (단, 부호 있는(signed)2진수는 2의 보수로 표현된다)
- 10101
- 11101
- 01101
- 10100
6. 다음 그래프의 정점 A에서부터 깊이 우선 탐색(DFS: Depth First Search)과 너비 우선 탐색(BFS: Breadth First Search)을 수행할 때, 방문 순서를 옳게 짝지은 것은? (단, 방문하지 않은 인접 정점이 2개 이상인 경우 알파벳 오름차순으로 방문한다)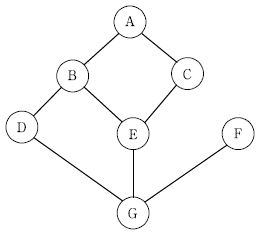
- DFS : A-B-D-G-F-C-E
BFS : A-B-C-D-E-F-G - DFS : A-B-D-G-F-C-E
BFS : A-B-C-D-E-G-F - DFS : A-B-D-G-E-C-F
BFS : A-B-C-D-E-F-G - DFS : A-B-D-G-E-C-F
BFS : A-B-C-D-E-G-F
7. 다음 후위(postfix) 표기식을 전위(prefix) 표기식으로 바꾼 것은? (단, 표기식에서 +, -, *, /는 연산자이고 A, B, C, D, E는 피연산자이다)
- - + A * / B C D E
- - / * + A B C D E
- + / * - A B C D E
- - + A / * B C D E
8. 가상 기억장치 기술에 대한 설명으로 옳지 않은 것은?
- 가상 주소(virtual address)에서 물리 주소(physical address)로의 주소 변환(address translation)이 이루어진다.
- 가상 주소와 물리 주소의 비트 수가 서로 다를 수 있다.
- 다중 프로그래밍 정도(degree of multiprogramming)가 높아짐에 따라 CPU 이용률(utilization)은 계속 높아진다.
- 서로 다른 프로세스가 동일한 물리 기억장치 영역을 공유할 수 있다.
9. 다음 2진 표현이 나타내는 IEEE 754 표준 단정도(single precision) 부동소수점 수의 값은?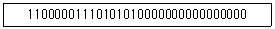
- +5.3125(10)
- -26.625(10)
- +21.25(10)
- -13.3125(10)
10. UNIX에서의 프로세스 간 통신(interprocess communication)에 대한 설명으로 옳지 않은 것은?
- 세마포어(semaphore) 동작은 중단될 수 없는 원자성을 가진다.
- 시그널(signal)은 커널 혹은 프로세스가 다른 프로세스에게 비동기적으로 특정 사건을 통지하는 데 사용된다.
- 지명 파이프(named pipe)를 통해 통신하는 프로세스 간에는 부모?자식 관계가 요구된다.
- 공유메모리(shared memory)에 대한 상호 배제(mutual exclusion)는 운영체제가 보장하지 않는다.
11. 폭포수(waterfall) 모델의 변형으로 산출물보다는 각 개발 단계의 테스트에 중점을 두며, 테스트 활동이 분석 및 설계와 어떻게 관련되어 있는지 보여 주는 소프트웨어 개발 모델은?
- 나선형(spiral) 모델
- 단계적 개발(phased development) 모델
- 원형(prototyping) 모델
- V 모델
12. 중앙처리장치와 주기억장치 사이에 있는 기억장치로서, 둘 사이의 속도 차이로 인한 컴퓨터 시스템 성능 저하를 경감하기 위한 것은?
- 캐시 기억장치
- 보조 기억장치
- ROM
- 레지스터
13. 관계형 데이터베이스 언어인 SQL에 대한 설명으로 옳은 것은?
- 데이터 정의어(DDL)를 이용하여 데이터를 검색한다.
- 데이터 조작어(DML)를 이용하여 권한을 부여하거나 취소한다.
- DELETE 문은 테이블을 삭제하는 데 사용한다.
- SELECT 문에서 FROM 절은 필수 항목이고, WHERE 절은 선택 항목이다.
14. 삽입 정렬을 사용하여 자료를 오름차순으로 정렬한다. 초기 및 2회전 후의 자료가 다음과 같다면 4회전 후의 결과는?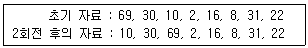
- 2, 10, 16, 30, 69, 8, 31, 22
- 8, 2, 10, 30, 16, 69, 22, 31
- 16, 2, 10, 30, 69, 8, 22, 31
- 2, 10, 30, 69, 16, 8, 31, 22
15. 다음 Java 언어로 작성한 프로그램의 실행 결과는?
- 100
0.0 - 100
Array Index Out Of Bounds Exception - 150
Arithmetic Exception - 150
/ by zero at Test.main(Test.java:14)
16. TCP 헤더에 포함된 필드에 대한 설명으로 옳은 것만을 모두 고른 것은?
- ㄱ, ㄴ
- ㄱ, ㄷ
- ㄷ, ㄹ
- ㄴ, ㄹ
17. 함수 수행을 위한 정보가 저장되는 프로세스 메모리 영역은?
- 데이터(data) 영역
- 힙(heap) 영역
- 스택(stack) 영역
- 텍스트(text) 영역
18. 전가산기(FA: Full Adder)는 두 입력 A, B 및 입력캐리 Ci를 더해서 합 S와 출력캐리 Co를 만들어 내는 회로이다. 4개의 전가산기를 사용한 다음 연산기에서 오버플로우(overflow)가 발생한 경우가 아닌 것은?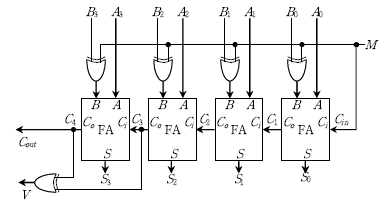
- M = 0, Cout = 1, 부호 없는(unsigned) 연산으로 해석
- M = 1, Cout = 1, 부호 없는 연산으로 해석
- M = 0, V = 1, 2의 보수를 사용하는 부호 있는(signed) 연산으로 해석
- M = 1, V = 1, 2의 보수를 사용하는 부호 있는 연산으로 해석
19. 다음 C 프로그램의 실행 결과는?
- 0
- 12
- 19
- 20
20. 운영체제가 프로세스(process)를 생성하는 과정을 순서대로 바르게 나열한 것은?
- ㄱ→ㄴ→ㄷ→ㄹ
- ㄱ→ㄷ→ㄹ→ㄴ
- ㄷ→ㄹ→ㄱ→ㄴ
- ㄷ→ㄹ→ㄴ→ㄱ
오답 노트
TCP는 신뢰성 있는 스트림 전송 제공: 맞음
TCP는 연결 지향형 프로토콜: 맞음
IP는 비연결 지향형 프로토콜: 맞음