1과목: 데이터 베이스
1. 막대한 양의 자료를 각종 매체에 저장하는 기법을 파일 조직, 파일 편성 혹은 파일 구성 방법이라 한다. 일반적으로 많이 사용되는 파일 조직 방법 중에서 키 값에 따라 순차적으로 정렬된 데이터를 저장하는 데이터 지역(Data Area)과 이 지역에 대한 포인터를 가진 색인 지역(Index Area)으로 구성된 파일은?
- 색인 순차 파일(Indexed Sequential File)
- 링 파일(Ring File)
- 직접 파일(Direct File)
- 순차 파일(Sequential File)






2. 관계 데이터모델이 가지는 제약조건 중 다음 설명에 해당하는 것은?
- 릴레이션 무결성
- 외래키 무결성
- 참조 무결성
- 개체 무결성

3. 일반적인 데이터 모델의 3가지 구성 요소로 옳은 것은?
- 구조, 연산, 제약조건
- 구조, 연산, 도메인
- 릴레이션, 구조, 스키마
- 데이터사전, 연산, 릴레이션
4. 뷰(VIEW)에 대한 설명으로 옳은 내용 모두를 나열한 것은?
- ①, ②
- ①, ③, ④
- ②, ③, ④
- ①, ②, ③, ④
5. 다음 영문의 ( ) 안에 적합한 단어는?
- stack
- queue
- graph
- tree
 의 문장은 "모든 삽입은 한쪽 끝(rear)에서 발생하고, 모든 삭제는 반대쪽 끝(front)에서 발생한다"는 내용을 설명하고 있으므로, 선입선출(FIFO) 구조인 queue가 정답입니다.
의 문장은 "모든 삽입은 한쪽 끝(rear)에서 발생하고, 모든 삭제는 반대쪽 끝(front)에서 발생한다"는 내용을 설명하고 있으므로, 선입선출(FIFO) 구조인 queue가 정답입니다.
6. 데이터베이스의 정의로 옳은 내용 모두를 나열한 것은?
- ①, ②, ④
- ①, ③, ④
- ②, ③, ④
- ①, ②, ③, ④
7. SQL을 사용 용도에 따라 분류할 경우, 다음 중 성격이 다른 하나는?
- SELECT
- DROP
- ALTER
- CREATE
8. 데이터 모델의 종류 중 오너-멤버(owner-member) 관계를 갖는 것은?
- 뷰 데이터 모델
- 네트워크 데이터 모델
- 계층 데이터 모델
- 관계 데이터 모델
9. 다음 트리를 전위 순서(Pre-order)로 운행한 결과는?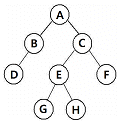
- D B G H E F C A
- A B D C E G H F
- D B A G E H C F
- B D G H E F A C
 트리에서 Root $\rightarrow$ Left $\rightarrow$ Right 순으로 방문하는 방식입니다.
트리에서 Root $\rightarrow$ Left $\rightarrow$ Right 순으로 방문하는 방식입니다.
10. 버블 정렬을 이용한 오름차순 정렬시 다음 자료에 대한 3회전 후의 결과는?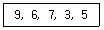
- 3, 5, 6, 7, 9
- 6, 3, 5, 7, 9
- 6, 7, 3, 5, 9
- 9, 7, 6, 5, 3
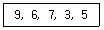 자료 [9, 6, 7, 3, 5]를 오름차순 정렬하면 다음과 같습니다.
자료 [9, 6, 7, 3, 5]를 오름차순 정렬하면 다음과 같습니다.
11. 한 릴레이션(relation)에 포함되어 있는 튜플(tuple)의 수를 무엇이라 하는가?
- 차수(degree)
- 카디널리티(cardinality)
- 도메인(domain)
- 속성(attribute)
12. 어떤 릴레이션 R에서 X와 Y를 각각 R의 애트리뷰트 집합의 부분 집합이라고 할 경우, 애트리뷰트 X의 값 각각에 대하여 시간에 관계없이 항상 애트리뷰트 Y의 값이 오직 하나만 연관되어 있을 때 Y는 X에 함수 종속이라고 한다. 이러한 성질을 표현한 것으로 옳은 것은?
- X → Y
- Y → X
- X ⊂ Y
- Y ⊂ X
13. 데이터베이스 설계 단계 중 물리적 설계 단계에 해당하지 않는 것은?
- 저장 레코드 양식 설계
- 접근 경로 설계
- 레코드 집중의 분석 및 설계
- 트랜잭션 인터페이스 설계
14. 정규화 과정 중 2NF에서 3NF 로 진행시의 작업에 해당하는 것은?
- 부분적 함수 종속 제거
- 결정자이면서 후보 키가 아닌 것 제거
- 이행적 함수 종속 제거
- 다치 종속 제거
15. 다음 그림에서 트리의 차수는?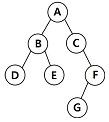
- 1
- 2
- 3
- 4

16. 데이터베이스 설계 순서를 바르게 나열한 것은?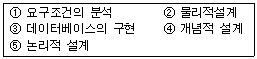
- ①→②→③→④→⑤
- ①→③→②→④→⑤
- ①→④→⑤→②→③
- ①→②→④→③→⑤
17. DBMS의 필수 기능 중 다음 내용과 관계있는 것은?
- Manipulation Facility
- Definition Facility
- Connection Facility
- Control Facility

18. 순서가 A, B, C, D 로 정해진 입력 자료를 스택에 입력하였다가 출력한 결과가 될 수 없는 것은?
- D, A, B C
- C, D, B, A
- B, C, D, A
- C, B, A, D
19. 다음 설명에 해당되는 것은?
- DBMS
- Schema
- Key
- DataWare House

20. 다음 자료 구조 중 성격이 나머지 셋과 다른 하나는?
- 스택
- 큐
- 데크
- 트리
2과목: 전자 계산기 구조
21. 주소지정 방식 중 오퍼랜드가 메모리상의 데이터 주소를 기억하고 그 주소에 기억되어 있는 데이터에 접근하는 방식은?
- 간접 주소지정 방식
- 상태 주소지정 방식
- 인덱스 주소지정 방식
- 즉시 주소지정 방식
22. 한 워드가 8비트이고, 총 32개의 워드를 저장하는 ROM이 있다. 입력주소 선은 몇 개 필요한가?
- 4
- 5
- 8
- 32
23. 자외선을 사용하여 기억된 내용을 지우는 소자는?
- UVEPROM
- EEPROM
- Mask ROM
- PROM
24. 시프트 레지스터에서 왼쪽으로 한번 시프트 시키면 원래의 데이터는?
- 1/2배로 된다.
- 1/4배로 된다.
- 2배로 된다.
- 4배로 된다.
25. 다음 중 부동소수점 연산에서 정규화를 하는 주목적은?
- 연산 속도를 증가시키기 위해서
- 숫자 표시를 간단히 하기 위해서
- 수의 정밀도를 높이기 위해서
- 부호 비트를 생략하기 위해서
26. 다음 중 인터럽트의 요청 신호 플래그를 순차적으로 검사하여 원인을 판별하는 방식은?
- DMA
- 스트로브
- 데이지 체인
- 폴링
27. 함수연산기능 인스트럭션의 수행에 필요한 피연산자를 기억시킬 레지스터의 종류에 따라 컴퓨터 구조를 분류할 때, 이에 속하지 않는 것은?
- 스택 컴퓨터구조
- AC 컴퓨터구조
- 리스트 컴퓨터 구조
- 범용 레지스터 컴퓨터구조
28. 다음 중 AND 마이크로 동작과 유사한 것은?
- insert 동작
- OR 동작
- packing 동작
- mask 동작
29. 메모리 인터리빙(interleaving) 방법의 사용 목적이 되는 것은?
- 메모리 액세스의 효율 증대
- 기억 용량의 증대
- 입·출력 장치의 증설
- 전력 소모 감소
30. RS 플립플롭을 JK 플립플롭으로 바꾸어 사용하려고 할 때 필요한 게이트는?
- OR 게이트 2개
- AND 게이트 2개
- EX-OR 게이트 2개
- NAND 게이트 2개
31. 다음 중 범용 레지스터를 사용하여 기억할 수 없는 것은?
- 연산할 데이터
- 연산된 결과
- 실행될 명령어
- 주기억장치에서 보내온 데이터
32. 아래 논리식을 간략화 하면?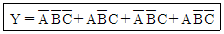
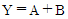
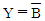
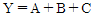
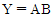
33. 다음 진리표(truth table)를 간략히 한 결과 Y는?(문제 오류 입니다. 정답은 A + B'이 답입니다. 보기에 답이 없으므로 여기서는 4번을 누르시면 정답 처리 됩니다.)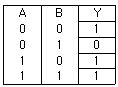
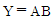
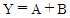
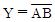
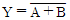
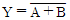 를 정답으로 처리합니다.
를 정답으로 처리합니다.
34. 다음 중 자기보수코드(self complement code)는?
- Hamming code
- Excess-3 code
- Gray code
- 6-3-1-1 code
35. 인터럽트에 대한 설명으로 옳지 않은 것은?
- 데이지 체인은 하드웨어로 우선순위를 결정한다.
- 주변장치의 우선순위는 일반적으로 속도가 빠른 장치에 높은 우선순위를 부여한다.
- 하드웨어에 의한 우선순위 부여는 유연성이 있고, 인터럽트 반응 시간이 빠르다.
- 우선순위를 부여하는 방법으로 소프트웨어와 하드웨어에 의한 방법이 있다.
36. 32가지의 서로 다른 동작을 수행하고, 직접 주소지정방식과 간접 주소지정방식을 선택적으로 사용할 수 있으며, 4개의 레지스터를 가진 컴퓨터의 기억장치의 크기가 4Kbyte라 할 때 명령어의 크기는 몇 bit 인가?
- 32
- 20
- 12
- 16
37. 다음 명령(Instruction) 중에서 PC←X와 같은 의미를 뜻하는 것은?
- JMP X
- ADD X
- MOV X
- STA X
38. 한 개의 마이크로 오퍼레이션 수행에 필요한 시간을 무엇이라 하는가?
- micro cycle time
- seek time
- search time
- access time
39. 일정한 시간 간격으로 발생한 펄스에 따른 계산기의 각 부분의 동작을 규칙적으로 진행시키는 제어 방식은?
- 직류 방식
- 비동기식 제어 방식
- 비주기식 제어 방식
- 동기식 제어 방식
40. 인스트럭션은 중앙처리장치를 이용하여 수행되는데 다음 중 명령을 읽어내는 사이클(cycle)은?
- fetch 사이클
- execute 사이클
- indirect 사이클
- interrupt 사이클
3과목: 시스템분석설계
41. 경리 장부 처리시 차변, 대변의 한계 값을 체크하는데 사용하는 방법으로 대차의 균형이나 가로, 세로의 합계가 일치하는가를 체크하는 방법은?
- Limit check
- Matching check
- Balance check
- Batch total check
42. 코드 설계 단계 중 대상 항목에 대하여 설계된 코드의 사용이 컴퓨터 처리 내에 한정되는가? 해당 업무에만 한정되는가? 관련 부문의 업무에 공통으로 사용되는가? 기업 전체에 사용되는가? 등을 확정하는 단계는?
- 사용 기간의 결정
- 코드화 방식의 결정
- 사용 범위의 결정
- 코드 대상 항목 결정
43. 색인 순차 파일의 색인 영역에 해당하지 않는 것은?
- Track Index Area
- Cylinder Index Area
- Master Index Area
- Overflow Index Area
44. 프로세스 설계에 대한 설명으로 옳지 않은 것은?
- 정확성을 고려하여 처리과정을 명확히 명시한다.
- 프로세스의 분류 처리는 가능한 상세하고 크게 한다.
- 시스템의 상태나 구성 요소 등을 종합적으로 표시한다.
- 정보의 흐름이나 처리 과정은 모든 사람이 이해할 수 있는 표준화 방법을 사용한다.
45. 모듈 작성시 주의사항으로 옳지 않은 것은?
- 자료의 추상화와 정보 은닉 개념을 도입한다.
- 적절한 크기로 작성한다.
- 모듈 내용이 다른 곳에서도 적용이 가능하도록 표준화한다.
- 모듈간의 기능적 결합도는 최대화한다.
46. 한 모듈이 다른 모듈의 내부 기능 및 그 내부 자료를 조회하는 경우의 결합성은?
- stamp coupling
- common coupling
- content coupling
- control coupling
47. 표준 처리 패턴 중 특정 조건이 주어진 파일 중에서 그 조건에 만족되는 것과 그렇지 않은 것으로 분리 처리하는 것은?
- merge
- collate
- extract
- distribution
48. 폭포수 모형에 대한 설명으로 옳지 않은 것은?
- 단계별 정의가 분명하고 전체 공조의 이해가 용이하다.
- 두 개 이상의 과정이 병행하여 수행되지 않는다.
- 실제 개발될 소프트웨어에 대한 시제품을 만들어 최종 결과물을 예측한다.
- 전통적인 생명주기 모형이다.
49. 럼바우의 객체지향 분석 기법에서 자료 흐름도와 밀접한 관계가 있는 것은?
- Object Modeling
- Dynamic Modeling
- Function Modeling
- Total Modeling
50. 파일의 종류 중 일시적인 성격을 지닌 정보를 기록하는 것은?
- Transaction file
- Backup file
- Source data file
- Master file
51. 다음은 어떤 종류의 코드 오류(error)인가?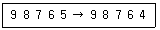
- Transposition error
- Random error
- Transcription error
- Double Transport error
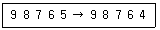 처럼 데이터를 옮겨 적는 과정에서 잘못 기재하는 전사 오류(Transcription error)에 해당합니다.
처럼 데이터를 옮겨 적는 과정에서 잘못 기재하는 전사 오류(Transcription error)에 해당합니다.
52. 시스템 문서화의 효과와 거리가 가장 먼 것은?
- 시스템 개발 후 시스템의 유지 보수가 용이하다.
- 시스템 개발팀에서 운용팀으로 인계, 인수가 쉽다.
- 시스템 개발 중 추가 변경에 따른 혼란을 방지한다.
- 시스템 에러 발생시 책임 소재를 분명히 한다.
53. 자료 흐름도에 대한 설명으로 옳지 않은 것은?
- 기능별로 분할하고 다차원적이다.
- 자료 흐름도는 논리적으로 일관성이 있어야한다.
- 처리 공정은 원, 자료저장소는 이중직선, 종착지는 사각형, 자료 흐름은 점선으로 표시한다.
- 시스템의 활동적인 구성 요소 및 그들 간의 연관관계를 모형화 한다.
54. 시스템의 특성 중 다음 설명에 해당하는 것은?
- 목적성
- 정보성
- 제어성
- 종합성

55. 다음과 같이 코드화 대상 항목의 속성을 표시하는 의미가 있는 물체의 크기나 무게 등을 코드 일부에 숫자 형태 그대로 사용하는 코드 분류 방법은?
- Significant Digit Code
- Sequence Code
- Block Code
- Decimal Code

56. 출력 설계 단계 중 다음 사항과 관계되는 것은?
- 출력 정보 내용의 설계
- 출력 정보 매체화의 설계
- 출력 정보 분배에 대한 설계
- 출력 정보 이용에 대한 설계
 이미지에서 제시된 사용 목적 결정, 이용자 및 경로 결정, 이용 주기 및 시기 결정, 기밀성 및 보존 결정은 모두 출력된 정보를 어떻게 사용할 것인가를 정의하는 출력 정보 이용에 대한 설계 단계에 해당합니다.
이미지에서 제시된 사용 목적 결정, 이용자 및 경로 결정, 이용 주기 및 시기 결정, 기밀성 및 보존 결정은 모두 출력된 정보를 어떻게 사용할 것인가를 정의하는 출력 정보 이용에 대한 설계 단계에 해당합니다.
57. 입력 정보의 설계 순서로 옳은 것은?
- ①→②→③→④
- ②→③→④→①
- ③→④→①→②
- ④→①→②→③
 이미지의 순서에 따라 입력 정보의 발생 $\rightarrow$ 수집 $\rightarrow$ 매체화 $\rightarrow$ 투입 순으로 진행되는 것이 옳습니다.
이미지의 순서에 따라 입력 정보의 발생 $\rightarrow$ 수집 $\rightarrow$ 매체화 $\rightarrow$ 투입 순으로 진행되는 것이 옳습니다.
58. 시스템의 기본 요소에 대한 기능 설명이 옳지 않은 것은?
- Control : 시스템의 기본 요소들이 각 과정을 올바르게 행하는지 감독, 관리하는 행위
- Output : 처리된 결과를 시스템에서 추출하는 행위
- Input : 처리를 위한 데이터나 조건 등을 시스템에 투입하는 행위
- Feedback : 입력된 데이터를 처리, 가공하는 행위
59. 처리결과를 마이크로필름에 출력하는 장치로서 서류를 대량으로 장시간 보존하는 장치는?
- CAM
- ROM
- COM
- RAM
60. 파일설계 단계 중 다음 사항과 관계되는 것은?
- 파일 항목 검토
- 파일 특성 조사
- 파일 매체 검토
- 파일 편성법 검토
 의 처리 주기, 처리 방식, 갱신 빈도 및 형태, 파일의 활동률은 모두 파일의 성격과 이용 형태를 분석하는 파일 특성 조사 단계에 해당합니다.
의 처리 주기, 처리 방식, 갱신 빈도 및 형태, 파일의 활동률은 모두 파일의 성격과 이용 형태를 분석하는 파일 특성 조사 단계에 해당합니다.
4과목: 운영체제
61. 다중 처리기 운영체제의 주/종(Master/Slave) 구조에 서 각각의 기능에 대한 연결이 옳은 것은?
- Master : 입출력 담당, Slave : 연산 및 입출력 담당
- Master : 연산 담당, Slave : 입출력 담당
- Master : 연산 담당, Slave : 연산 및 입출력 담당
- Master : 연산 및 입출력 담당, Slave : 연산 담당
62. 현재 헤드의 위치는 100번 트랙이며, 바깥쪽에서 안쪽으로 진행 중이었다. 디스크 대기 큐에 다음과 같은 순서의 액세스 요청이 대기 중이다. SSTF 스케줄링 기법을 사용할 경우 제일 먼저 처리되는 트랙은? (단, 가장 안쪽 트랙은 0 이다.)
- 16
- 40
- 90
- 102
63. 자원 보호 기법 중 접근 제어 행렬에서 수평으로 있는 각 행들만을 따온 것으로서 각 영역에 대한 권한은 객체와 그 객체에 허용된 연산자로 구성되는 것은?
- Global Table
- Access Control List
- Capability List
- Lock/Key
64. UNIX에서 커널의 기능이 아닌 것은?
- 프로세스 관리 기능
- 기억장치 관리 기능
- 입, 출력 관리 기능
- 명령어 해독 기능
65. 대기시간 45, 서비스 시간 5일 때 HRN 스케줄링 기법을 사용했을 경우 우선순위 계산 결과는?
- 25
- 10
- 2
- 1
66. 프로세스의 정의로 옳은 내용 모두를 나열한 것은?
- ①, ④
- ①, ②, ④
- ②, ③, ④
- ①, ②, ③, ④
67. 분산 처리시스템에서 완전연결(fully connected) 구조에 대한 설명으로 옳은 것은?
- 각 노드가 시스템 내의 모든 노드와 직접 연결되어 있다.
- 모든 사이트가 하나의 중앙 사이트에 직접 연결되어 있다.
- 시스템 내의 모든 사이트들이 공유 버스에 연결된 구조이다.
- 시스템 내의 각 사이트가 인접하는 다른 두 사이트와만 직접 연결된 구조이다.
68. 15K의 작업을 16K의 작업공간에 할당했을 경우, 사용된 기억장치 배치전략 기법은?
- First-Fit
- Best-Fit
- Worst-Fit
- Last-Fit
 이미지에서 $15\text{K}$ 작업을 수용할 수 있는 공간($20\text{K}, 16\text{K}, 30\text{K}$) 중 가장 크기가 작은 $16\text{K}$ 공간에 할당했으므로 Best-Fit에 해당합니다.
이미지에서 $15\text{K}$ 작업을 수용할 수 있는 공간($20\text{K}, 16\text{K}, 30\text{K}$) 중 가장 크기가 작은 $16\text{K}$ 공간에 할당했으므로 Best-Fit에 해당합니다.
69. UNIX 시스템의 특징이 아닌 것은?
- 온라인 대화형 시스템이다.
- 다중 작업 시스템이다.
- 다중 사용자 시스템이다.
- 이식성이 낮은 시스템이다.
70. PCB에 대한 설명으로 옳지 않은 것은?
- PCB에는 프로세스 식별 번호, 프로세스 상태 정보, CPU레지스터 정보 등이 수록되어 있다.
- 적절한 응답시간이 보장되므로 일괄처리 시스템에 유용하다.
- 운영체제가 프로세스 관리를 위해 필요한 정보를 PCB에 수록한다.
- “Process Control Block"을 의미한다.
71. 파일 디스크립터에 포함되는 내용이 아닌 것은?
- 파일의 이름
- 보조기억장치에서의 파일의 위치
- 생성된 날짜와 시간
- 파일 오류에 대한 수정 방법
72. 가상기억 장치의 페이지 교체 알고리즘 중에서 한 프로세스에서 사용되는 각 페이지마다 계수기를 두어 현 시점에서 볼 때 가장 오래 전에 사용된 페이지를 대치하는 것은?
- LIFO(Last In First Out)
- FIFO(First In First Out)
- LRU(Least Recently Used)
- LFU(Least Frequently Used)
73. Round-Robin 스케줄링(Scheduling) 방식에 대한 설명으로 옳지 않은 것은?
- 할당된 시간(Time Slice) 내에 작업이 끝나지 않으면 대기 큐의 맨 뒤로 그 작업을 배치한다.
- 시간 할당량이 충분히 크면 FIFO 방식과 비슷하다.
- 적절한 응답시간이 보장되므로 일괄처리 시스템에 유용하다.
- 시간 할당량이 작아질수록 문맥교환 과부하는 상대적으로 높아진다.
74. 운영체제의 기능으로 거리가 먼 것은?
- 원시 프로그램을 목적 프로그램으로 변환하는 기능
- 데이터 및 자원의 공유 기능
- 자원을 효율적으로 관리하기 위한 자원의 스케줄링 기능
- 사용자와 시스템 간의 편리한 인터페이스 기능
75. 키 값으로부터 주소 변환을 위해서는 해시 함수나 색인 테이블을 사용하는 파일 구조는?
- 순차 파일
- 직접 파일
- 분할 파일
- 색인 순차 파일
76. 운영체제의 목적 중 다음 사항과 가장 관계되는 것은?
- 처리 능력 증대
- 응답 시간 단축
- 신뢰도 향상
- 사용 가능도 증대
 에서 제시된 시스템의 정확한 동작 정도, 하드웨어 오류의 자체 회복, 소프트웨어 오류 메시지 제공 등은 시스템이 얼마나 믿을 수 있는지를 나타내는 신뢰도 향상에 관한 설명입니다.
에서 제시된 시스템의 정확한 동작 정도, 하드웨어 오류의 자체 회복, 소프트웨어 오류 메시지 제공 등은 시스템이 얼마나 믿을 수 있는지를 나타내는 신뢰도 향상에 관한 설명입니다.
77. 운영체제의 설계 목적으로 가장 타당한 것은?
- 처리량의 향상과 응답시간의 증가
- 처리량의 향상과 응답시간의 단축
- 처리량의 감소와 응답시간의 단축
- 처리량의 감소와 응답시간의 증가
78. 3 페이지가 들어갈 수 있는 기억장치에서 다음과 같은 순서로 페이지가 참조될 때 FIFO 기법을 사용하면 페이지 부재(page fault)는 몇 번 일어나는가? (단, 현재 기억장치는 모두 비어 있다고 가정한다.)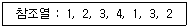
- 3
- 4
- 5
- 6
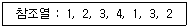 의 참조열에 따른 페이지 부재 과정은 다음과 같습니다.
의 참조열에 따른 페이지 부재 과정은 다음과 같습니다.
79. 페이지 크기에 대한 설명으로 옳지 않는 것은?
- 페이지 크기가 클수록 프로그램 수행에 불필요한 내용까지도 주기억장치에 적재될 수 있다.
- 페이지 크기가 작을수록 페이지 맵 테이블의 크기가 커진다.
- 페이지 크기가 클수록 마지막 페이지의 내부 단편화가 줄어든다.
- 페이지 크기가 작을수록 전체적인 입출력 시간은 늘어난다,
80. 교착 상태의 해결 방안 중 은행원 알고리즘과 관계되는 것은?
- Recovery
- Detection
- Prevention
- Avoidance
5과목: 정보통신개론
81. 오류를 제어할 때 수신측에서 오류의 검출기능과 정정기능을 동시에 갖는 부호는?
- Hamming Code
- Parity Code
- ASC Ⅱ Code
- EBCDIC Code
82. FDDI에 대한 설명으로 틀린 것은?
- FDDI는 한 개의 링으로 구성된다.
- 물리계층에 해당하는 프로토콜은 PHY, PMD가 있다.
- 토큰 매체 액세스 제어방법으로 작동한다.
- 매체로 광섬유케이블을 사용한다.
83. 비동기식 전송의 특성으로 맞는 것은?
- 문자 위주 비트와 비트 위주로 나누어진다.
- 송신자와 수신자는 동기화의 시간을 설정하고 유지한다.
- 대용량, 고속의 데이터 전송에 주로 쓰인다.
- 한 번에 한 문자씩 전송한다.
84. 비패킷형 단말이 패킷교환망을 이용할 수 있도록 패킷의 조립과 분해 기능을 제공해 주는 것은?
- DSU
- MODEM
- PAD
- CCU
85. OSI-7 계층 중 응용간의 대화제어(dialogue control)를 담당하는 것은?
- Session Layer
- Application Layer
- Presentation Layer
- Data Link Layer
86. 프로토콜 구성요소에 해당하지 않는 것은?
- 구문(syntax)
- 의미(semantics)
- 파라미터(parameter)
- 순서(timing)
87. 정보의 전달을 위한 단계가 바르게 나열된 것은?
- 링크확립-회로연결-메시지전달-회로절단-링크절단
- 링크확립-회로연결-메시지전달-링크절단-회로절단
- 회로연결-링크확립-메시지전달-회로절단-링크절단
- 회로연결-링크확립-메시지전달-링크절단-회로절단
88. HDLC 전송 프레임에서 시작 플래그 다음에 전송되는 필드는?
- 제어부
- 주소부
- 정보부
- FCS
89. 비동기식 전송 시 포함되는 내용이 아닌 것은?
- 시작 비트
- 데이터
- 플래그 비트
- 정지 비트
90. HDLC(High-level Data Link Control) 동작모드에 해당하지 않는 것은?
- 정규 응답 모드(NRM)
- 비동기 응답 모드(ARM)
- 비동기 균형 모드(ABM)
- 동기 균형 모드(SBM)
91. 두 개의 채널사이에 보호대역(guard band)을 사용하여 인접한 채널간의 간섭을 막는 다중화방식은?
- 시분할 다중화방식
- 주파수분할 다중화방식
- 코드분할 다중화방식
- 공간분할 다중화방식
92. 통신망 구성형태 중 중앙집중식 구조를 가지고 포인트 투 포인트 링크로 연결하는 방식은?
- 성형
- 망형
- 트리형
- 링형
93. 매체 접근방식에 의한 LAN의 분류에 해당되지 않는 것은?
- 이더넷
- 토큰 링
- 토큰 버스
- 캐리어 밴드
94. 데이터 통신시스템의 구성에서 데이터 전송계에 해당하지 않는 것은?
- 단말장치(DTE)
- 데이터 전송회선
- 통신 제어장치
- 데이터 처리장치
95. 패킷교환 방식에 대한 설명으로 옳지 않은 것은?
- 음성 전송과 같은 실시간 통신에 적합하다.
- 저장-전달 방식을 사용한다.
- 전송할 수 있는 패킷의 길이는 제한되어 있다.
- 데이터 그램과 가상회선 방식으로 구분된다.
96. 코덱(CODEC)에 대한 설명으로 옳은 것은?
- 데이터통신망 관리를 위한 디지털 장치이다.
- 데이터통신망에 의해 정보를 제어하는 장치이다.
- 데이터를 모아 일괄로 처리하는 장치이다.
- 아날로그 신호를 디지털 전송로에 맞게 디지털 신호로 바꾸어 전송해 주는 장치이다.
97. 디지털 변조에서 디지털 데이터를 아날로그 신호로 변환시키는 방식으로 틀린 것은?
- ASK
- PCM
- FSK
- PSK
98. 양방향으로 데이터 전송이 가능하나, 한 순간에는 한쪽 방향으로만 전송이 이루어지는 방식은?
- 단방향방식
- 반이중방식
- 양방향방식
- 전이중방식
99. 통신제어장치에 대한 설명으로 가장 옳은 것은?
- 데이터의 입출력을 담당한다,
- 시스템 상호간을 접속하는 통신로이다.
- 아날로그 신호를 디지털 신호로 변환한다.
- 데이터 전송 시 필요한 제어신호를 송수신한다.
100. 통신회선의 채널용량을 증가시키기 위한 방법으로 적합하지 않은 것은?
- 신호 세력을 높인다.
- 잡음 세력을 줄인다,
- 데이터 오류를 줄인다.
- 채널 대역폭을 증가시킨다.