1과목: 데이터 베이스
1. 트랜잭션(Transaction)의 특성에 해당하지 않는 것은?
- Atomicity
- Consistency
- Isolation
- Distribution






2. 병행수행의 문제점 중 하나의 트랜잭션 수행이 실패한 후 회복되기 전에 다른 트랜잭션이 실패한 갱신 결과를 참조하는 현상은?
- uncommitted dependency
- lost update
- inconsistency
- cascading rollback
3. 자료구조 중 큐에 대한 설명으로 옳지 않은 것은?
- 선형 리스트의 한쪽에서 삽입이 이루어지고 다른 한쪽에서는 삭제가 이루어진다.
- 후입선출(LIFO) 방식으로 자료를 처리한다.
- 시작과 끝을 표시하는 두 개의 포인터가 있다.
- 운영체제의 작업 스케줄링에 응용되는 구조이다.
4. 뷰(View)에 대한 설명으로 옳지 않은 것은?
- 뷰는 데이터의 접근을 제어하게 함으로써 보안을 제공한다.
- 뷰는 데이터의 논리적인 독립성을 제공한다.
- 뷰로 구성된 내용에 대하여 삽입, 삭제, 갱신 연산에 제약사항이 없다.
- 뷰의 테이블은 가상 테이블이다.
5. 후위 표기(postfix)식이 다음과 같을 때 식의 계산 값은?(단, 표현된 수치는 한자리 숫자를 의미한다.)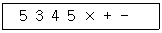
- 30
- 20
- 14
- -18
6. 해싱에서 서로 다른 두 개 이상의 레코드가 동일한 주소를 갖는 현상을 의미하는 것은?
- Synonym
- Collision
- Bucket
- Slot
7. 다음 설명에 해당하는 스키마의 종류는?
- 개념 스키마
- 내부 스키마
- 외부 스키마
- 관계 스키마
8. In computing, this is the process of rearranging an initially unordered sequence of records until they ordered. What is this?
- debugging
- loading
- sorting
- compiling
9. 관계형 데이터 베이스에서 릴레이션의 특성으로 옳지 않은 것은?
- 하나의 릴레이션에서 튜플의 순서는 없다.
- 각 속성의 명칭은 릴레이션 내에서 중복 사용 될수 있다.
- 모든 튜플은 서로 다른 값을 갖는다.
- 한 릴레이션에 나타난 속성 값은 원자 값이다.
10. 릴레이션 A는 4개의 튜플로 구성되어 있고, 릴레이션 B는 6개의 카티션 프로턱트 연산의 결과로서 몇 개의 튜플이 생성되는가?
- 2
- 6
- 10
- 24
11. 해싱 함수 선택시 고려 사항으로 거리가 먼 것은?
- 계산과정의 단순화
- 충돌의 최소화
- 기억장소 낭비의 최소화
- 오버플로우의 최대화
12. 다음 트리를 Preorder로 운행할 경우 첫 번째로 탐색하는 것은?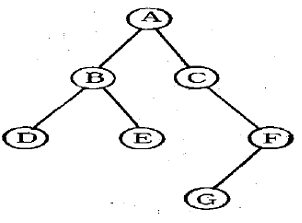
- A
- C
- E
- F
 에서 최상위 루트 노드는 A이므로, 가장 먼저 탐색하는 노드는 A가 됩니다.
에서 최상위 루트 노드는 A이므로, 가장 먼저 탐색하는 노드는 A가 됩니다.
13. 다음 관계 대수의 의미로 가장 타당한 것은?
- 이름, 학과, 물리학과를 속성으로 하는 전공 테이블 생성
- 학생 테이블에서 물리학과인 학생 이름 삭제
- 학생 테이블에서 물리학과인 학생 이름 조회
- 전공 테이블에서 학과의 이름을 물리학과로 변경
14. SQL의 명령어를 DCL, DML, DDL로 구분할 경우, 다음 중 성격이 다른 하나는?
- CREATE
- SELECT
- ALTER
- DROP
15. 버블 정렬을 이용한 오름차순 정렬시 다음 자료에 대한 2회전 후의 결과는?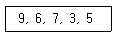
- 3,9,6,7,5
- 6,7,3,5,9
- 6,3,5,7,9
- 3,5,9,6,7
16. SQL에서 뷰(View) 생성시 사용하는 명령어는?
- CREATE
- ALTER
- UPDATE
- DROP
17. A→B 이고 B→C 일 때 A→C를 만족하는 종속 관계를 제거하는 정규화 단계는?
- 1NF → 2NF
- 2NF → 3NF
- 3NF → BCNF
- 비정규 릴레이션 → 1NF
18. 관계 대수와 관계 해석에 대한 설명으로 옳지 않은 것은?
- 관계 대수는 원하는 정보가 무엇이라는 것만 정의하는 비절차적인 특징을 가지고 있다.
- 관계 해석은 관계 데이터의 연산을 표현하는 방법이다.
- 관계 대수로 표현한 식은 관계 해석으로 표현할 수 있다.
- 관계 해석은 원래 수학의 프레디킷 해석에 기반을 두고 있다.
19. 데이터베이스 설계 중 가장 먼저 수행되는 것은?
- 논리적 설계 단계
- 개념적 설계 단계
- 물리적 설계 단계
- 요구조건 분석 단계
20. 양쪽 끝에서 노드의 삽입과 삭제가 허용되는 선형 리스트?
- 스택(stack)
- 큐(queue)
- 데크(deque)
- 연결 리스트(linked list)
2과목: 전자 계산기 구조
21. 2진수 1001에 대한 해밍 코드로 옳은 것은?
- 0011001
- 1000011
- 0100101
- 0110010
22. 오류 검출 코드가 아닌 것은?
- Biquinary
- Excess-3코드
- 2 out-of 5코드
- Hamming 코드
23. 인터럽트의 발생 원인으로 틀린 것은?
- 부프로그램 호출
- supervisor call
- 정전
- 불법적인 인스트럭션 수행
24. 다음 중 조합논리회로가 아닌 것은?
- 감산기
- 디코더
- 카운터
- 디멀티플렉서
25. 32가지의 서로 다른 동작을 수행하고, 직접주소 지정방식과 간접주소 지정방식을 선택적으로 사용할 수 있으며, 4개의 레지스터를 가진 컴퓨터의 기억장치의 크기가 4 KB(kilo byte)라 할 때 명령어의 크기는 몇 bit 인가?
- 32
- 20
- 16
- 12
26. 부동소수점 연산의 일반적인 형식은?
- 부호, 지수부, 가수부
- 지수부, 가수부
- 가수부, 지수부
- 부호, 가수부, 지수부
27. 보조기억 장치의 페이지 접근 횟수가 많아 작업 수행시간보다 페이징 교체시간이 많아지는 기억공간의 관리기법은?
- 분산 로딩 기법
- 페이징(Paging)
- 세그먼트
- 연속 로딩 기법
28. Floating Point Number에서 저장 비트가 필요 없는 것은?
- 부호
- 지수
- 소수점
- 소수(가수)
29. 다음과 같은 회로도의 조건 제어문은?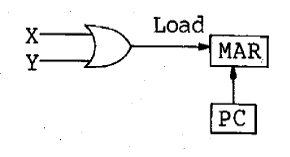
- (XY)‘ : PC→MAR
- (X+Y)‘ : PC→MAR
- X+Y: PC→MAR
- XY: PC→MAR
30. 메모리 인터리빙의 특징이 아닌 것은?
- CPU가 시분할하여 모듈들 (M1,M2,M3등)을 번갈아가면서 접근하는 방법이다.
- 캐시,고속 DMA 전송에 많이 사용되고 있다.
- 단위시간당 수행할 수 있는 명령어의 수를 감소 시킬 수 있다.
- 중앙처리장치의 쉬는 시간을 줄일 수 있다.
31. 인스트럭션(Instruction)의 구성 중 오퍼랜드(Operand) 부분에 포함되지 않는 것은?
- 자료(Data)의 주소
- 자료(Data)
- 주소를 위한 정보(Information)
- 명령의 형식
32. 다음 중 데이터 레지스터에 속하지 않는 것은?
- Stack
- Accumulator
- Program Counter
- General Purpose Register
33. 다음 ( ) 안의 내용으로 옳은 것은?
- 여수(與數)
- 보수(complement)
- 2 진수
- 8 진수
34. 다음 중 결선 게이트의 특징이 아닌 것은?
- 논리 기능을 부여할 수 없다.
- 회로 비용을 절감 할 수 있다.
- open collector TTL로 게이트들의 출력단자를 묶어서쓴다.
- 게이트들의 출력 단자를 직접 연결한다.
35. 기억장치 내에 있는 내용을 이용하여 데이터를 찾을 수 있는 기억장치는?
- Main 기억장치
- Virtual 기억장치
- Auxiliary 기억장치
- Associative 기억장치
36. RAM에 대한 설명 중 옳지 않은 것은?
- Bipolar RAM은 TTL F/F으로 구성할 수 있다.
- SRAM은 일정한 사이클마다 재생시켜야 한다.
- 정보의 기입과 독출이 가능하다.
- MOS RAM은 F/F 으로 구성할 수 있다.
37. 다음 설명 중 틀린 것은?
- 중앙처리장치에서 연산한 결과 등을 일시적으로 저장해 두는 레지스터를 누산기라 한다.
- 입출력장치는 주변장치에 해당된다.
- 레지스터에서 기억장치로 정보를 옮기는 것을 로드(load)라 한다.
- 기억장치내의 데이터를 다른 기억장치로 옮기는 것을 전송이라 한다.
38. 데이터 단위가 8비트인 메모리에서 용량이 8192byte인 경우 어드레스 핀의 개수는?
- 12개
- 13개
- 14개
- 15개
39. 주소 버스가 8 비트로 256개의 주소가 할당되어 있는 시스템에서 각 장치 당 두 개씩의 주소가 할당되어 128개의 I/O장치들이 접속할 수 있는 주소 지정 방식은?
- 분리형 I/O (isolated-I/O)
- 인터럽트-구동 I/O (inteerrupt-driven-I/O)
- 기억 장치-사상 I/O(memory-mapped-I/O)
- 데이지-체인(daisy-chain)
40. 비교적 저속의 입출력 장치를 제어하는 채널의 종류는?
- 멀티플렉서 채널
- 인터럽트 채널
- 셀렉트 채널
- 시리얼 채널
3과목: 시스템분석설계
41. 소프트웨어 위기의 발생 요인에 대한 설명으로 가장 거리가 먼 것은?
- 소프트웨어 개발 인력 부족과 그에 따른 인건비가 상승한다.
- 다양한 소프트웨어의 요구에 따라 수요는 증가하지만 공급이 이를 따라가지 못한다.
- 소프트웨어 개발 시간이 지연되고 개발비용의 초과가 발생한다.
- 급속히 발전하는 소프트웨어에 비해 하드웨어의 생산 활동이 보조를 맞추지 못한다.
42. 전표처리에서 원장 또는 대장에 해당되는 파일로서 데이터 처리 시스템에서 중추적 역할을 담당하며 기본이 되는 데이터의 축척 파일은?
- Transaction file
- History file
- Master file
- Summary file
43. 시스템 개발 단계 중 입출력 자료 및 코드의 설계가 수행되는 단계는?
- 유지 보수 단계
- 상세 설계 단계
- 조사 분석 단계
- 시스템 구현 단계
44. 시스템 개발 시 문서화의 효과에 대한 설명으로 거리가 먼 것은?
- 시스템 개발 단계에서의 요식적 행위이다.
- 효율적인 소프트웨어 개발관리가 용이하다.
- 시스템 개발 중 추가 변경에 따른 혼란을 방지한다.
- 시스템 개발 후에 유지보수가 용이하다.
45. 흐름도의 종류 중 컴퓨터로 처리하는 부분을 중심으로 자료 처리에 필요한 모든 조작을 표시하고, 컴퓨터에 의한 처리 내용 및 조건, 입출력 데이터의 종류와 출력 등을 컴퓨터의 기능에 맞게 논리적으로 정확하게 설명한 것은?
- 블록 차트
- 시스템 흐름도
- 프로세스 흐름도
- 프로그램 흐름도
46. 다음의 입력 설계 단계 중 가장 마지막 단계에 해당하는 것은?
- 입력 정보의 매체화
- 입력 정보의 투입
- 입력 정보의 수집
- 입력 정보의 내용
47. 정해진 규정이나 한계, 또는 궤도로부터 상태나 현상을 벗어나지 않도록 미리 감지하고, 빠르게 진행되도록 하는 시스템의 특성은 무엇인가?
- 목적성
- 자동성
- 종합성
- 제어성
48. 코드의 종류 중 코드화 대상 항목을 자료의 발생 순서, 크기 순서, 가나다라 순서 등과 같이 어떤 일정한 기준에 따라 일련 번호를 부여하는 것은?
- block code
- group code
- sequence code
- decimal code
49. 프로그램 모듈화에 대한 설명으로 옳지 않은 것은?
- 시스템 개발시 시간과 노동력을 절감할 수 있다.
- 시스템 개발비용을 절감 할 수 있다.
- 프로그램의 신뢰도를 향상시킬 수 있다.
- 새로운 프로그램 기법 습득 기회를 증가시킬 수 있다.
50. 코드 설계 시 유의사항으로 거리가 먼 것은?
- 분류 기준 및 갱신이 용이해야 한다.
- 코드 추가시 확장이 용이해야 한다.
- 코드 체계의 중복성을 증가시켜야 한다.
- 의미가 1:1로 대응 되어야 한다.
51. 객체지향기법에서 객체가 메시지를 받아 실행해야 할 때 객체의 구체적인 연산을 정의한 것은?
- Instance
- Message
- Class
- Method
52. 자료 흐름도의 구성 요소 중 다음 설명에 해당 하는 것은?
- data flow
- process
- terminator
- data store
53. Waterfall 모형에 대한 설명으로 옳지 않은 것은?
- 단계별 정의가 분명하고 전체 공조의 이해가 용이하다,
- 두 개 이상의 과정이 병행하여 수행되지 않는다.
- 실제 개발될 소프트웨어에 대한 시제품을 만들어 최종 결과물을 예측한다.
- 전통적인 생명 주기 모형이다.
54. 다음 중 파일설계 단계 중 가장 먼저 수행되는 것은?
- 파일 특성 조사
- 파일 매체 검토
- 파일 항목 검토
- 편성법 검토
55. 표준 처리 패던 중 어느 특정의 조건을 주어진 파일 중에서 그 조건을 만족하는 것과 만족하지 않는 것으로 분산 처리하는 것은?
- Distribution
- Extract
- Collate
- Generate
56. 코드의 기능으로 거리가 먼 것은?
- 식별 기능
- 분류 기능
- 배열 기능
- 호환 기능
57. 파일 설계 시 파일매체 검토 단계에서의 기능 사항이 아닌 것은?
- 파일의 활동률 검토
- 정보량의 검토
- 조작의 용이성 검토
- 처리 시간의 검토
58. 다음과 같은 특징을 갖는 출력 매체 시스템은?
- CRT 출력 시스템
- COM 시스템
- X-Y 플로터
- 음성 출력 시스템
 의 특징인 '마이크로 필름 기록', '축소 보관', '반영구적 매체'는 COM(Computer Output Microfilm) 시스템의 핵심 특징입니다.
의 특징인 '마이크로 필름 기록', '축소 보관', '반영구적 매체'는 COM(Computer Output Microfilm) 시스템의 핵심 특징입니다.
59. 프로세스 설계 순서로 가장 옳은 것은?
- 기본사항확인→ 작업설계→ 처리방식설계
- 작업설계→ 기본사항확인→ 처리방식설계
- 처리방식설계→ 작업설계→ 기본사항확인
- 기본사항확인→ 처리방식설계→ 작업설계
60. 출력 설계 순서가 옳은 것은?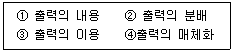
- ① →④ →② →③
- ④ →② →③ →①
- ② →③ →① →④
- ③ →① →④ →②
4과목: 운영체제
61. 초기 헤드의 위치가 100번 트랙이고 디스크 대기 큐에 다음과 같은 순서의 액세스 요청이 대기 중이다. SSTF 스케줄링 기법을 사용할 경우 가장 마지막에 처리되는 트랙은?
- 16
- 65
- 90
- 112
62. 기억장치 관리 전략 중 최적 적합 (Best-Fit) 방법으로 배치할 때 13K 요구하는 작업은 어느 위치에 배치되는가?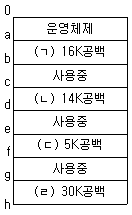
- (ㄱ)
- (ㄴ)
- (ㄷ)
- (ㄹ)
63. Process Control Block(PCB)의 내용이 아닌 것은?
- 프로세스의 현재 상태
- 프로세스 식별자
- 프로세스의 우선순위
- 페이지 부재(page fault) 발생 횟수
64. UNIX에서 컴퓨터가 부팅될 때 주기억장치에 적재된 후 시스템이 꺼질 때까지 항상 주기억장치에 상주하여 기억장치관리, 프로세스관리, 파일입출력 등을 수행하는 부분은?
- kernel
- i -node
- shell
- PCB
65. “Working Set"의 설명으로 옳은 것은?
- 단위 시간 동안 처리된 작업의 집합
- 하나의 일(Job)을 구성하는 페이지 집합
- 오류 데이터가 포함되어 있는 페이지 집합
- 하나의 프로세스가 자주 참조하는 페이지 집합
66. 운영체제 성능 평가 기준 중 시스템을 사용할 필요가 있을 때 즉시 사용 가능한 정도를 의미하는 것은?
- Turn Around Time
- Availability
- Reliability
- Throughput
67. UNIX의 특징으로 옳지 않는 것은?
- 대화식 운영체제이다.
- 다중 사용자, 다중 작업을 지원한다.
- 리스트 구조의 파일 시스템을 갖는다.
- 대부분 C 언어로 작성되어 이식성이 높다.
68. 운영체제의 설계 목표가 아닌 것은?
- 빠른 응답시간
- 처리량 향상
- 경과 시간 증가
- 폭 넓은 이식성
69. 모니터에 대한 설명으로 틀린 것은?
- 자료 추상화와 정보 은폐 개념을 기초로 한다.
- 병행 다중 프로그램밍에서 상호 배제를 구현하기 위한 특수 프로그램 기법이다.
- 구조적인 면에서 공유 데이터와 이 데이터를 처리하는 프로시저의 집합이라 할 수 있다.
- 모니터 외부의 프로세스도 모니터 내부 데이터를 직접 액세스 할 수 있다.
70. 다음의 a, b, c, d 작업에 대하여 운영체제가 CPU 스케줄링 기법으로 HRN 방식을 구현했을 때 우선순위가 가장 높은 작업은?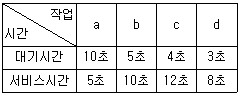
- a
- b
- c
- d
71. 파일 디스크립터에 대한 설명으로 옳지 않은 것은?
- 보조기억장치상의 파일의 위치 및 최초 수정 날짜 및 시간에 대한 정보를 포함한다.
- 파일 시스템이 관리하므로 사용자가 직접 참조할 수 없다.
- 보조기억장치에 저장되어 있다가 파일이 개방(Open)될 때 주기억장치로 옮겨지는 것이 일반적이다.
- 파일마다 독립적으로 존재한다.
72. 교착 상태 발생의 필요충분조건의 아닌 것은?
- Traffic Controller
- Circular Wait
- Hold And Wait
- Mutual Exclusion
73. 가변분할 다중 프로그래밍 시스템에서 인접한 공백들을 더 큰 하나의 공백으로 합하는 과정을 무엇이라 하는가?
- 기억장소의 페이징(paging)
- 기억장소의 통합(coalescing)
- 기억장소의 집약(compaction)
- 기억장소의 단편화(fragmentation)
74. 프로세스 정의로 적당하지 않은 것은?
- 하드웨어에 의해 사용되는 입출력 장치
- 실행중인 프로그램
- 운영체제 내에 프로세스 제어 블록의 존재로서 명시되는 것
- 프로세서가 할당되는 개체
75. 교착 상태 발생의 필요충분조건 4가지에 대한 설명으로 옳지 않은 것은?
- 상호배제: 최소한 하나의 자원이 공유 방식으로 점유되어야 한다.
- 점유 및 대기: 최소한 하나의 자원을 점유하고 있는 프로세스가 있어야 하며, 이 프로세스가 다른 프로세스에 의하여 점유된 자원을 추가로 얻기 위해 대기하고 있어야 한다.
- 비선점 : 자원들을 선점하지 못한다.
- 순환(환형)대기: 대기하고 있는 프로세스의 집합 {P₀,P1,---Pn}에서 P₀은 P1이 점유한 자원을 대기하고, P1은 P2를 대기하며, Pn은 P₀가 점유한 자원을 요청하기 위해 대기한다.
76. 다중 처리기(Multi - Processor) 운영체제 구조 중 주종 (Master/Slave) 처리기에 대한 설명으로 옳지 않은 것은?
- 하나의 프로세서를 주(Master)프로세서로 지정하고, 나머지들은 종(Slave)프로세서로 지정한다.
- 운영체제의 수행은 주(Master)프로세서가 담당한다.
- 주(Master)프로세서와 종(Slave)프로세서가 동시에 입출력을 수행하므로 대칭 구조를 갖는다.
- 주((Master)프로세서가 고장나면 전체 시스템이 다운된다.
77. 다음 접근제어 리스트에서 “파일1” 이 처리될 수 없는 것은?(단, R= 읽기, W=쓰기, P=인쇄, L=공유)
- 읽기
- 쓰기
- 인쇄
- 공유
 표를 보면 파일1의 권한은 (A, RWP)로 읽기(R), 쓰기(W), 인쇄(P)만 허용되어 있으며, 공유(L) 권한은 포함되어 있지 않으므로 처리될 수 없습니다.
표를 보면 파일1의 권한은 (A, RWP)로 읽기(R), 쓰기(W), 인쇄(P)만 허용되어 있으며, 공유(L) 권한은 포함되어 있지 않으므로 처리될 수 없습니다.
78. 하이퍼 큐브 구조에서 각 CPU가 5개의 연결점을 가질 경우 CPU의 총 개수는?
- 4
- 16
- 32
- 64
79. 다음 표와 같이 작업이 제출되었을 때, SJF 정책을 사용하여 스케줄링하면 평균 대기시간은?
- 2
- 3
- 4
- 5
80. 페이징 기법에 대한 설명으로 옳지 않은 것은?
- 외부 단편화가 방지된다.
- 페이지의 위치 정보를 가지고 있는 페이지 맵 테이블이 필요하다.
- 프로그램을 가변적인 크기로 나눈 후 주기억장치에 적재시켜 실행시키는 기법이다.
- 내부 단편화가 발생할 수 있다.
5과목: 정보통신개론
81. 패킷교환방식에 관한 설명으로 적합하지 않은 것은?
- 가상회선 방식과 데이터그램 방식이 있다.
- 아날로그 데이터 전송에 최적화되어 있다.
- 속도, 프로토콜 및 코드 변환이 가능하다.
- 장애발생시 대체경로 선택이 가능하다.
82. LAN의 매체 접근 제어 방식 중 Token Passing 방식에 사용되는 Token의 기능으로 맞는 것은?
- 채널의 사용권
- 노드의 수
- 전송매체
- 패킷 전송량
83. 다음 중 한번에 2개의 비트를 전송할 수 있는 신호레벨을 가지고 있을 때 채널용량은 얼마인가?(단, 대역폭은 3100Hz이고, 채널 상에 잡음 은 없는 것으로 가장 한다.)
- 3100bps
- 6200bps
- 9300bps
- 12400bps
84. MHS(Message Handling System)에 대한 설명으로 바르지 않은 것은?
- MS는 메시지를 축척하는 사서함 기능을 갖는다.
- 사용자간의 메시지를 송수신 하는 기능을 갖는다.
- MHS는 UA, MTA, MS 등으로 구성된다.
- 신호변환 및 정보처리가 가능 하다.
85. 정보통신 시스템의 구성요소 중 정보전송계의 요소가 아닌 것은?
- 신호변환장치
- 전송 회선
- 중앙처리장치
- 통신제어장치
86. 다음 중 무선 랜(Wireless LAN)의 표준 규격으로 옳은 것은?
- IEEE 802.1
- IEEE 802.3
- IEEE 802.11
- IEEE 802.15
87. 꼬임선 (Twisted-pair line)의 특징으로 맞지 않는 것은?
- 전기적 간섭현상을 줄이기 위해서 균일하게 서로 감겨있는 형태의 케이블이다.
- 하나의 케이블에 여러 쌍의 꼬임선들을 절연체로 피복하여 구성한다.
- 다른 전송률 면에서 제한적이지 않다.
- 가격이 저렴하고 설치가 간편한 이점을 가진다.
88. 다중화 방식 중 Time Division Multiplexing에 대한 설명으로 옳은 것은?
- Bandwidth의 이용도가 높아 고속 전송에 용이하다.
- 전송속도가 낮은 Sub-channel의 신호를 서로 다른 주파수 대역으로 변조 한다.
- Asynchronous Data만을 Multiplexing 하는데 사용 한다.
- Sub-channel간의 상호 간섭을 방지하기 위해 완충지역으로 Guard band가 필요하다.
89. 정보통신시스템의 구성 요소에 대한 설명으로 거리가 먼 것은?
- CCU, FEP는 통신 제어 장치이다.
- MODEM은 변복조 장치이다.
- DTE는 데이터 에러 감시 장치이다.
- DSU는 신호 변환 장치이다.
90. 데이터 교환방식 중 에러제어가 제공되지 않는 것은?
- 메시지 교환방식
- 데이터그램 패킷 교환방식
- 회선 교환방식
- 가상회선 패킷 교환방식
91. 전송제어 문자 중에서 수신된 정보 메시지에 대한 부정적인 응답의 의미를 가진 것은?
- ACK
- ENQ
- DLE
- NAK
92. 다음 중 데이터 회선종단장치와 관련이 없는 것은?
- DCE
- DTE
- MODEM
- DSU
93. 다음 중 전송 회선의 분류에서 유도매체가 아닌 것은?
- Twisted-pair cable
- Coaxiai cable
- Optical fiber
- Air
94. 다음 중 서비스에 따른 정보통신의 분류에 해당되지 않는 것은?
- 음성전화통신
- 화상및영상통신
- 멀티미디어통신
- 광 케이블 통신
95. 다음 중 ISDN의 기본 액세스 인터페이스는?
- B + 2D
- 2(B+D)
- 2B+D
- B+D
96. 프리젠테이션(Presentation)계층에서 제공되는 기능은?
- 흐름제어
- 에러제어
- 데이터 압축
- 분산 데이터베이스 액세스
97. OSI 7 계층에서 각 계층의 프로토콜 데이터 유닛(PDU)을 잘못 나타낸 것은?
- 데이터링크계층-프레임(Frame)
- 네트워크계층-블럭(Block)
- 전송계층- 세그먼트(Segment)
- 세션계층- 메시지(Message)
98. 송﹑수신이 동시에 가능하지 않은 전송방식은?
- 반이중방식
- 전이중방식
- 군별2선방식
- 4선방식
99. 다음 중 OSI 7계층 참조모델에서 중계기능, 경로설정 등을 주로 수행하는 계층은?
- 네트워크 계층
- 응용 계층
- 데이터링크 계층
- 표현 계층
100. 다음 중 교환방식에 관한 설명으로 틀린 것은?
- 회선교환방식은 회선에 융통성이 요구되거나 메시지가 짧은 경우에 적합하다.
- 데이터그램 패킷교환방식은 부하가 적거나 간헐적인 통신의 경우에 적합하다.
- 패킷교환방식은 코드 및 속도 변환이 가능하다.
- 가상회선 패킷교환방식은 패킷도착순서가 고정적이다.
오답 노트
Atomicity: 모두 반영되거나 전혀 반영되지 않아야 함
Consistency: 완료 후 DB 상태가 일관되어야 함
Isolation: 트랜잭션 간 상호 간섭이 없어야 함