1과목: 과목 구분 없음
1. 참고정보서비스에서 행하는 간접서비스 기능에 해당 하지 않는 것은?
- 서지데이터베이스의 구비
- 서지정보의 확인
- 참고집서의 평가
- 자원파일의 구축






2. <보기 1>에 제시된 질문의 유형에 대한 설명으로 옳은 것을 <보기 2>에서 모두 고른 것은?
- ㄱ, ㄴ
- ㄴ, ㄷ
- ㄷ, ㄹ
- ㄱ, ㄴ, ㄷ
 의 질문은 '법령을 찾습니까? 아니면 통계를 찾습니까'와 같이 답변자에게 제한된 선택지를 제공하는 폐쇄형 질문(Closed-ended question)입니다.
의 질문은 '법령을 찾습니까? 아니면 통계를 찾습니까'와 같이 답변자에게 제한된 선택지를 제공하는 폐쇄형 질문(Closed-ended question)입니다.
3. 브레이빅(Breivik)의 정보 리터러시 우산(Information Literacy Umbrella)에 해당하지 않는 것은?
- 도서관 리터러시(Library Literacy)
- 컴퓨터 리터러시(Computer Literacy)
- 네트워크 리터러시(Network Literacy)
- 데이터 리터러시(Data Literacy)
4. 엘리스(Ellis)의 정보탐색 모형에서 정보행위가 일어나는 순서대로 가장 바르게 나열한 것은?
- 시작-브라우징-추출-검증-차별화-종결
- 시작-연결-차별화-추출-검증-종결
- 시작-브라우징-차별화-검증-추출-종결
- 시작-연결-추출-차별화-검증-종결
5. 협력형 디지털 참고 봉사 서비스의 모델인 ‘Question Point’에 대한 설명으로 가장 옳지 않은 것은?
- LC와 OCLC가 함께 개발한 글로벌 협력형 디지털 참고정보서비스의 대표적인 예이다.
- 최소의 비용으로 24시간, 7일 동안 지속적으로 서비스를 제공할 수 있다.
- 국제 협력을 통하여 대내외적으로 조직 및 기관 위상을 정립할 수 있다.
- 수서업무 프로세스 개선과 자료구입 예산 집행의 효율성이 향상된다.
6. 학술 데이터베이스와 주제 분야를 짝지은 것으로 옳은 것은?
- MLA International Bibliography-법률 분야
- ABI/INFORM Complete -경제·경영 분야
- PAIS International -화학 분야
- WestLaw-문학 분야
7. <보기>는 자동색인의 색인어 추출과 선정 과정을 나타낸 것이다. 과정에 대한 설명으로 가장 옳지 않은 것은?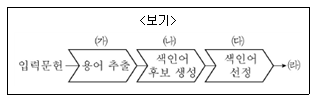
- ㈎: 문장 단위의 용어 추출 기법
- ㈏: 불용어 제거
- ㈐: 통계적 기법과 비통계적 기법으로 선정
- ㈑: 색인어 리스트
8. <보기>는 색인작업 시 미리 조합하여 만들어 놓은 색인어를 이용하여 정보를 검색하는 방법 가운데 하나를 설명한 글이다. ㉠에 가장 알맞은 단어는?
- 용어열 색인
- 유니텀 색인
- 주제명 색인
- 패싯분류
9. 인용색인은 정보자료에 수록되어 있는 인용된 자료와 인용한 자료를 체계적으로 편성한 색인이다. 이에 대한 설명으로 가장 옳지 않은 것은?
- 인용된 문헌과 인용한 문헌들은 지적인 상관관계가 있다고 할 수 있다.
- 색인작성 과정에 색인자의 개입이 불필요하다.
- 해외의 대표적인 인용색인 서비스인 SCOPUS는 Social Sciences Citation Index와 Science Citation Index를 제공한다.
- 국내에서는 한국연구재단이 운영하는 Korea Citation Index 등이 있다.
10. 정보검색 모형 중 질의와 문헌의 매칭 원리가 가장 다른 하나는?
- 불리언 모형
- 잠재의미색인 모형
- 신경망 모형
- 추론망 모형
11. 학술지 A에는 2014년에 10편, 2015년에 10편, 2016년에 20편의 논문이 수록되어 있다. 그리고 2016년 한 해 동안 전 주제 분야에서 학술지 A의 2014년 발행된 논문을 30회, 2015년 발행된 논문을 30회, 2016년 발행된 논문을 40회 인용하였다. 학술지 A의 2016년 기준 영향력 지수(Impact Factor)는?
- 1.5
- 2
- 2.5
- 3
12. 정보자료는 가공 여부에 따라 1차자료와 2차자료로 구분할 수 있다. 2차자료에 해당하는 것을 <보기>에서 모두 고른 것은?
- ㄱ, ㄴ
- ㄱ, ㄷ
- ㄱ, ㄴ, ㄷ
- ㄴ, ㄷ, ㄹ
13. <보기>에서 설명하는 자료유형의 영문 명칭은?
- Patent
- Preprint
- White paper
- Proceedings
14. MODS(Metadata Object Description Schema)의 장점으로 가장 옳지 않은 것은?
- 데이터요소가 더블린코어보다 풍부하다.
- 디지털자원의 여러 측면에 대한 데이터 표현이 가능하다.
- MARC21레코드를 MODS로 변환하고 이 데이터를 다시 MARC로 완벽하게 변환 가능하다.
- 다양한 장르의 디지털자원에 대한 서지정보 기술이 가능하다.
15. <보기>가 설명하고 있는 용어로 가장 적합한 것은?
- LOD
- MOOC
- Open API
- Virtual International Authority File
16. 참고사서의 ‘학자로서의 자질’을 강조함으로써 사서의 전문성을 재정의한 사람은?
- Jesse Shera
- William A. Katz
- James I. Wyer
- Armstrong
17. <보기>가 설명하고 있는 학술지 평가지수는?
- Impact Factor
- Journal Cited Half-Life
- SJR Indicator
- Article Influence Score
18. 브라우징(Browsing) 검색의 특징에 대한 <보기>의 설명 중 옳은 것을 모두 고르면?
- ㄱ, ㄴ
- ㄴ, ㄷ
- ㄷ, ㄹ
- ㄱ, ㄴ, ㄷ
19. <보기>에서 설명하는 디지털 장서관리 방법은?
- 컨스펙터스(Conspectus)
- 서지기술법(Bibliographic Description)
- 판도라(PANDORA)
- 디콜렉션(dCollection)
20. 대상 객체가 지니고 있는 여러 자질을 이용하여 유사성 등을 계산하고 유사성 거리가 가까운 객체들끼리 그룹이 되는 군집화 과정에서 사용되는 측정 도구에 대한 설명으로 가장 올바르게 연결된 것은?
- 거리계수: 두 대상의 속성이 일치하는 정도를 측정하는 방법
- 상관계수: 두 대상을 표현하는 분류자질들의 벡터 쌍에 대한 독립성을 측정하는 방법
- 연관계수: 두 사건 확률변수 간의 의존적인 관계를 수량화하여 나타내는 방법
- 확률적 유사계수: 벡터 공간상 대상 간의 상이성을 측정하는 방법