1과목: 과목 구분 없음
1. 다음은 컴퓨터 언어처리에 관련된 시스템 S/W의 기능을 설명한 것이다. 옳지 않은 것은?
- 컴파일러 : 고급언어를 이진목적모듈로 변환기능
- 어셈블러 : 객체지향언어를 이진목적모듈로 변환기능
- 링커 : 여러 목적모듈을 통합하여 실행 가능한 하나의 모듈로 변환기능
- 로더 : 실행 가능한 모듈을 주기억장치에 탑재기능






2. 컴퓨터에서 사건이 발생하면 이를 처리하기 위해 인터럽트 기술을 사용한다. 사건의 발생지에 따라 동기와 비동기 인터럽트로 분류된다. 다음 중 비동기 인터럽트는?
- 프로세스가 실행 중에 0으로 나누기를 할 때 발생하는 인터럽트
- 키보드 혹은 마우스를 사용할 때 발생하는 인터럽트
- 프로세스 내 명령어 실행 때문에 발생하는 인터럽트
- 프로세스 내 명령어가 보호 메모리영역을 참조할 때 발생하는 인터럽트
3. 데이터통신에서 에러 복구를 위해 사용되는 Go-back-N ARQ에 대한 설명으로 옳지 않은 것은?
- Go-back-N ARQ는 여러 개의 프레임들을 순서번호를 붙여서 송신하고, 수신 측은 이 순서번호에 따라 ACK 또는 NAK를 보낸다.
- Go-back-N ARQ는 송신 측은 확인응답이 올 때까지 전송된 모든 프레임의 사본을 갖고 있어야 한다.
- Go-back-N ARQ는 재전송 시 불필요한 재전송 프레임들이 존재하지 않는다.
- Go-back-N ARQ는 송신 측은 n개의 Sliding Window를 가지고 있어야 한다.
4. 데이터베이스에서 뷰(View)에 대한 설명으로 옳은 것은?
- 뷰는 테이블을 기반으로 만들어지는 가상 테이블이며, 뷰를 기반으로 새로운 뷰를 생성할 수 없다.
- 뷰 삭제는 SQL 명령어 중 DELETE 구문을 사용하며, 뷰 생성에 기반이 된 기존 테이블들은 영향을 미치지 않는다.
- 뷰 생성에 사용된 테이블의 기본키를 구성하는 속성이 포함되어 있지 않은 뷰도 데이터의 변경이 가능하다.
- 뷰 생성 시 사용되는 SELECT문에서 GROUP BY 구문은 사용 가능하지만, ORDER BY 구문은 사용할 수 없다.
5. 초기에 빈 Binary Search Tree를 생성하고, 입력되는 수는 다음과 같은 순서로 된다고 가정한다. 입력되는 값을 이용하여 Binary Search Tree를 만들고 난 후 Inorder Traversal을 했을 때의 방문하는 순서는?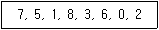
- 01235678
- 02316587
- 75103268
- 86230157
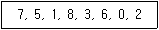 의 데이터를 삽입하여 트리를 구성한 후, 중위 순회(Inorder Traversal)를 수행하면 항상 오름차순으로 정렬된 결과가 나옵니다.
의 데이터를 삽입하여 트리를 구성한 후, 중위 순회(Inorder Traversal)를 수행하면 항상 오름차순으로 정렬된 결과가 나옵니다.
6. 통신 S/W 구조에서 제2계층인 데이터링크 계층의 주기능이 아닌 것은?
- 데이터링크 계층에서 전송할 프레임(Frame) 제작 기능
- 점대점(Point to Point) 링크 간의 오류제어 기능
- 종단(End to End) 간 경로설정 기능
- 점대점(Point to Point) 링크 간의 흐름제어 기능
7. 다음 중 집적도가 가장 높은 회로와 가장 큰 저장용량 단위를 나타낸 것은?
- ULSI, PB
- VLSI, TB
- MSI, GB
- SSI, PB

8. 다음은 다중스레드(Multi-Thread)에 관련된 설명이다. 옳지 않은 것은?
- 하나의 프로세스에 2개 이상의 스레드들을 생성하여 수행한다.
- 스레드별로 각각의 프로세스를 생성하여 실행하는 것보다 효율적이다.
- 스레드들 간은 IPC(InterProcess Communication)방식으로 통신한다.
- 각각의 스레드는 프로세스에 할당된 자원을 공유한다.
9. 다음과 같이 3개의 프로세스가 있다고 가정한다. 각 프로세스의 도착 시간과 프로세스의 실행에 필요한 시간은 아래표와 같다. CPU 스케줄링 알고리즘으로 RR(Round Robin)을 사용한다고 가정한다. 3개의 프로세스가 CPU에서 작업을 하고 마치는 순서는? (단, CPU를 사용하는 타임 슬라이스(time slice)는 2이다.)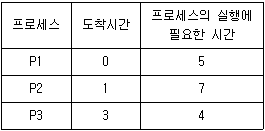
- P2, P1, P3
- P2, P3, P1
- P1, P2, P3
- P1, P3, P2
10. 다음의 C프로그램을 실행한 결과로 옳은 것은?
- 1 5 10 20
- 1 5 20 4
- 1 5 30 4
- 에러 발생
11. Flynn의 병렬컴퓨터 분류방식에 대한 설명으로 옳지 않은 것은?
- SISD - 명령어와 데이터를 순서대로 처리하는 단일프로세서 시스템이다.
- SIMD - 단일 명령어 스트림을 처리하고 배열프로세서라고도 한다.
- MISD - 여러 개의 프로세서를 갖는 구조로 밀결합 시스템(tightly-coupled system)과 소결합 시스템(looselycoupled system)으로 분류한다.
- MIMD - 여러 개의 프로세서들이 서로 다른 명령어와 데이터를 처리하는 진정한 의미의 병렬프로세서이다.
12. 네트워크 토폴로지(Topology) 중 버스(Bus) 방식에 대한 설명으로 옳지 않은 것은?
- 버스 방식은 네트워크 구성이 간단하고 작은 네트워크에 유용하며 사용이 용이하다.
- 버스 방식은 네트워크 트래픽이 많을 경우 네트워크 효율이 떨어진다.
- 버스 방식은 통신 채널이 단 한 개이므로 버스 고장이 발생하면 네트워크 전체가 동작하지 않으므로 여분의 채널이 필요하다.
- 버스 방식은 노드의 추가⋅삭제가 어렵다.
13. 정보은닉(information hiding)에 대한 설명으로 옳지 않은 것은?
- 필요하지 않은 정보는 접근을 제한하는 것이다.
- 모듈 사이의 독립성을 유지시킨다.
- 설계전략을 지역화하여 전략의 변경에 따른 영향을 최소화한다.
- 모듈 사이의 결합도를 높여 신뢰성을 향상시킨다.
14. 다음 전가산기 논리회로에 대한 설명으로 옳지 않은 것은?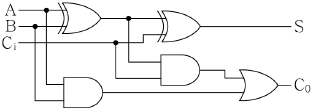
- 전가산기는 캐리를 포함하여 연산처리하기 위해 설계되었다.
- S = (A⊕B)⊕Ci
- C0 = AB+ACi+BCi
- 전가산기는 두 개의 반가산기만으로 구성할 수 있다.
15. 다음은 그래프 순회에서 깊이 우선 탐색 방법에 대한 수행 순서를 설명한 것이다. (ㄱ)~(ㄹ)에 알맞은 내용으로 짝지어진 것은?
- (ㄱ)Stack (ㄴ)push (ㄷ)pop (ㄹ)Stack
- (ㄱ)Stack (ㄴ)pop (ㄷ)push (ㄹ)Queue
- (ㄱ)Queue (ㄴ)enQueue (ㄷ)deQueue (ㄹ)Queue
- (ㄱ)Queue (ㄴ)enQueue (ㄷ)deQueue (ㄹ)Stack
16. 소프트웨어 개발 생명 주기(Software Development Life Cycle)의 순서로 옳은 것은?
- 계획 → 분석 → 설계 → 구현 → 테스트 → 유지보수
- 분석 → 계획 → 설계 → 구현 → 테스트 → 유지보수
- 분석 → 계획 → 설계 → 테스트→ 구현 → 유지보수
- 계획 → 설계 → 분석 → 구현 → 테스트 → 유지보수
17. 다음은 postfix 수식이다. 이 postfix 수식은 스택을 이용하여 연산을 수행한다. 그리고 ^는 지수함수 연산자이다. 처음 *(곱하기 연산) 계산이 되고 난 후 스택의 top과 top-1에 있는 두 원소는 무엇인가? (단, 보기의 '(top)'은 스택의 top 위치를 나타낸다.)
- (top) 6, 1
- (top) 9, 1
- (top) 2, 3
- (top) 2, 7
18. 빅데이터에 대한 설명으로 옳은 것은?
- 빅데이터는 정형데이터로만 구성되며, 소셜 미디어 데이터는 해당되지 않는다.
- 빅데이터를 구현하기 위한 대표적인 프레임워크는 하둡이 있으며, 하둡의 필수 핵심 구성 요소는 맵리듀스(MapReduce)와 하둡분산파일시스템(Hadoop Distributed File System)이다.
- 빅데이터 처리과정은 크게 수집 → 저장 → 처리 → 시각화(표현) → 분석 순서대로 수행된다.
- NoSQL은 관계 데이터 모델을 사용하는 RDBMS 중 하나이다.
19. 최근 컴퓨팅 환경이 클라우드 환경으로 진화됨에 따라 가상화 기술이 중요한 기술로 부각되고 있다. 이에 대한 설명으로 옳지 않은 것은?
- 하나의 컴퓨터에 2개 이상의 운영체제 운용이 가능하다.
- VM(Virtual Machine)하에서 동작되는 운영체제(Guest OS)는 실 머신에서 동작되는 운영체제보다 효율적이다.
- 특정 S/W를 여러 OS플랫폼에서 실행할 수 있어 S/W 이식성이 제고된다.
- VM하에서 동작되는 운영체제(Guest OS)의 명령어는 VM명령어로 시뮬레이션되어 실행된다.
20. 다음 C프로그램의 실행 결과는?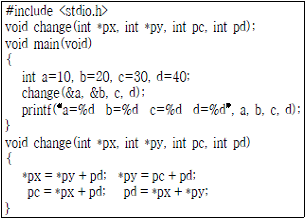
- a=60 b=70 c=50 d=30
- a=60 b=70 c=30 d=40
- a=10 b=20 c=50 d=30
- a=10 b=20 c=30 d=40
어셈블러는 어셈블리어(저급언어)를 기계어(이진 목적 모듈)로 변환하는 프로그램입니다. 객체지향언어를 변환하는 것은 컴파일러의 역할입니다.
오답 노트
컴파일러: 고급언어를 기계어로 변환하는 기능이 맞습니다.
링커: 여러 목적 모듈을 연결해 실행 파일로 만드는 기능이 맞습니다.
로더: 실행 파일을 메모리에 적재하는 기능이 맞습니다.