1과목: 과목 구분 없음
1. 중위 표기법으로 표현된 <보기>의 수식을 후위 표기법으로 옳게 표현한 것은?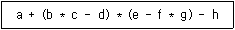
- ab * cd + efg * - * - h -
- abc * d + ef * g - * - h -
- abcd * - efg * + * - h -
- abc * d - efg * - * + h -






2. 소프트웨어 개발 프로세스 모델에 대한 설명으로 가장 옳지 않은 것은?
- 폭포수(Waterfall) 모델은 단계별 정형화된 접근 방법 및 체계적인 문서화가 용이하다.
- RAD(Rapid Application Development) 모델은 CASE(Computer Aided Software Engineering) 도구를 활용하여 빠른 개발을 지향한다.
- 나선형(Spiral) 모델은 폭포수(Waterfall) 모델과 원형(Prototype) 모델의 장점을 결합한 모델이다.
- 원형(Prototype) 모델은 고객의 요구를 완전히 이해하여 개발을 진행하는 것으로 시스템 이해도가 높은 관리자가 있는 경우 유용하다.
3. 서로 다른 시스템 간의 통신을 위한 표준을 제공함으로써 통신에 방해가 되는 기술적인 문제점을 제거하고 상호 인터페이스를 정의한 OSI 참조 모델의 계층에 대한 설명으로 가장 옳지 않은 것은?
- 네트워크 계층은 물리 계층에서 전달받은 데이터에 대한 동기를 확인하는 기능, 데이터의 원활한 전송을 제어하는 흐름제어(Flow Control) 기능, 안전한 데이터 전송을 위한 에러 제어(Error Control) 기능을 수행한다.
- 물리 계층은 상위 계층으로부터 전달받은 데이터의 물리적인 링크를 설정하고 유지, 해제하는 기능을 담당한다.
- 전송 계층은 통신하고 있는 두 사용자 사이에서 데이터 전송의 종단 간(end-to-end) 서비스 질을 높이고 신뢰성을 제어하는 기능을 담당한다.
- 응용 계층은 사용자가 직접 접하는 부분이며 전자 메일 서비스, 파일 전송 서비스, 네트워크 관리 등이 있다.
4. <보기> C 프로그램의 실행 결과는?
- 0
- 1
- 2
- 3
5. 정책 수립에 있어 중요성이 커지고 있는 빅데이터에 대한 설명으로 가장 옳지 않은 것은?
- 디지털 환경에서 생성되는 데이터로 규모가 방대하고, 생성 주기가 길며, 형태가 다양하다.
- 하둡(Hadoop)과 같은 오픈 소스 소프트웨어 시스템을 빅데이터 처리에 이용하는 것이 가능하다.
- 보건, 금융과 같은 분야의 빅데이터는 사회적으로 유용한 정보이나 데이터 활용 측면에서 프라이버시 침해에 대한 대비가 필요하다.
- 구글 및 페이스북, 아마존의 경우 이용자의 성향과 검색패턴, 구매패턴을 분석해 맞춤형 광고를 제공하는 등 빅데이터의 활용을 증대시키고 있다.
6. <보기>는 TCP/IP 프로토콜에 대한 설명이다. ㉠~㉡에 들어갈 내용으로 가장 옳은 것은?
- ㉠ ICMP ㉡ RARP
- ㉠ RARP ㉡ ICMP
- ㉠ ARP ㉡ ICMP
- ㉠ ICMP ㉡ ARP
7. 주기억 장치의 페이지 교체 기법에 대한 설명으로 가장 옳은 것은?
- FIFO(First In First Out)는 가장 오래된 페이지를 교체한다.
- MRU(Most Recently Used)는 최근에 적게 사용된 페이지를 교체한다.
- LRU(Least Recently Used)는 가장 최근에 사용한 페이지를 교체한다.
- LFU(Least Frequently Used)는 최근에 사용빈도가 가장 많은 페이지를 교체한다.
8. RAID(Redundant Array of Inexpensive Disks) 기술에 대한 설명으로 가장 옳지 않은 것은?
- RAID 1 레벨은 미러링(Mirroring)을 지원한다.
- RAID 3 레벨은 데이터를 블록 단위로 분산 저장하여 대용량의 읽기 중심 서버용으로 사용한다.
- RAID 5 레벨은 고정적인 패리티 디스크 대신 패리티가 모든 디스크에 분산되어 저장되므로 병목 현상을 줄여준다.
- RAID 6 레벨은 두 개의 패리티 디스크를 사용하므로 두 개의 디스크 장애 시에도 데이터의 복구가 가능하다.
9. 질의 최적화를 위한 질의문의 내부 형태 변화에 대한 규칙으로 가장 옳지 않은 것은?
- 실렉트(select) 연산은 교환적이다: σc1(σc2(R))≡σc2(σc1(R))
- 연속적인 프로젝트(project) 연산은 첫 번째 것을 실행하면 된다: ΠList1(ΠList2(…(ΠListn(R))…))≡ΠListn(R)
- 합집합(∪)과 관련된 프로젝트(project) 연산은 다음과 같이 변환된다: Π(A∪B)≡Π(A)∪Π(B)
- 실렉트의 조건 c가 프로젝트 속성만 포함하고 있다면 교환적이다: σc(Π(R))≡Π(σc(R))
10. <보기> 이진 트리의 내부 경로 길이(length)와 외부 경로 길이로 옳은 것은?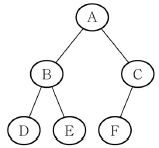
- 7, 20
- 7, 23
- 8, 20
- 8, 23

11. 8진수로 표현된 13754(8)를 10진수로 표현하면?
- 6224
- 6414
- 6244
- 6124
12. <보기> 잘 알려진 포트번호(well-known port)와 TCP 프로토콜이 바르게 연결된 것을 모두 고른 것은?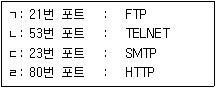
- ㄱ, ㄴ
- ㄱ, ㄹ
- ㄴ, ㄷ
- ㄴ, ㄹ
13. 파일 처리 시스템(File Process System)과 비교한 데이터 베이스관리 시스템(DBMS)에 대한 설명으로 가장 옳지 않은 것은?
- 응용 프로그램과 데이터 간의 상호 의존성이 크다.
- 데이터 중복을 최소화한다.
- 응용 프로그램의 요청을 수행한다.
- 데이터 공유를 수월하게 한다.
14. 임계지역(critical section) 문제에 대한 해결책이 가져야 하는 성질로 가장 옳지 않은 것은?
- 한 번에 한 프로세스만이 임계지역을 수행하도록 해야 한다.
- 프로세스는 자신이 임계지역을 수행하지 않으면서 다른 프로세스가 임계지역을 수행하는 것을 막으면 안된다.
- 프로세스의 임계지역 진입은 유한 시간 내에 이루어져야 한다.
- 임계지역 문제의 해결책에서는 프로세스의 수행 속도에 대해 적절한 가정을 할 수 있다.
15. <보기> C 프로그램의 출력은?
- 40 5
- 40 6
- 45 5
- 45 6
16. <보기> 회로의 종류를 바르게 연결한 것은?
- ㄱ: 조합논리회로, ㄴ: 조합논리회로
- ㄱ: 조합논리회로, ㄴ: 순차논리회로
- ㄱ: 순차논리회로, ㄴ: 조합논리회로
- ㄱ: 순차논리회로, ㄴ: 순차논리회로
17. CISC(Complex Instruction Set Computer)에 대한 설명으로 가장 옳은 것은?
- 고정 길이의 명령어 형식을 가진다.
- 명령어의 길이가 짧다.
- 다양한 어드레싱 모드를 사용한다.
- 하나의 명령으로 복잡한 명령을 수행할 수 없어 복잡한 하드웨어가 필요하다.
18. 퀵 정렬에 대한 설명으로 가장 옳지 않은 것은?
- 퀵 정렬은 분할 정복(divide and conquer) 방식으로 동작한다.
- 퀵 정렬의 구현은 흔히 재귀 함수 호출을 포함한다.
- n개의 데이터에 대한 퀵 정렬의 평균 수행 시간은 O(logn)이다.
- C.A.R. Hoare가 고안한 정렬 방식이다.
19. 나시-슈나이더만(N-S) 차트의 반복(While) 구조에 대한 표현으로 가장 옳은 것은?
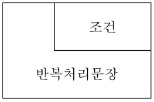



 가 이 구조를 정확하게 표현하고 있습니다.
가 이 구조를 정확하게 표현하고 있습니다.
20. <보기> C 프로그램의 실행 결과로 화면에 출력되는 숫자가 아닌 것은?
- 1
- 3
- 5
- 7
1. $(b * c - d)$ $\rightarrow$ $bc*d-$
2. $(e - f * g)$ $\rightarrow$ $efg*-$
3. $a + (bc*d-) * (efg*-) - h$ $\rightarrow$ $a bc*d- efg*- * + h -$ 순으로 변환됩니다.