1과목: 과목 구분 없음
1. C 프로그램을 컴파일하면 <보기>와 같은 것들이 실행 된다. 이 중 3번째로 실행되는 것은?
- 링커(linker)
- 어셈블러(assembler)
- 전처리기(preprocessor)
- 컴파일러(compiler)






2. 유닉스 파일 시스템에 대한 설명으로 가장 옳지 않은 것은?
- 슈퍼블록은 전체 블록의 수, 블록의 크기, 사용 중인 블록의 수 등 파일 시스템의 정보를 가지고 있다.
- 아이노드는 파일의 종류, 크기, 소유자, 접근 권한 등 각종 속성 정보를 가지고 있다.
- 파일마다 데이터 블록, 아이노드 외에 직접 블록 포인터와 단일·이중·삼중 간접 블록 포인터로 구성된 인덱스 정보를 가진 인덱스 블록을 별도로 가지고 있다.
- 디렉터리는 하위 파일들의 이름과 아이노드 포인터 (또는 아이노드 번호)를 포함하는 디렉터리 엔트리들로 구성된다.
3. <보기>는 8비트에 부호 있는 2의 보수 표현법으로 작성한 이진수이다. 이에 해당하는 십진 정수는?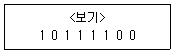
- -60
- -68
- 94
- 188
4. <보기>가 설명하는 것은?
- 명령어 레지스터
- 프로그램 카운터
- 데이터 레지스터
- 주소 레지스터
5. 운영체제에서 가상 메모리의 페이지 교체 기법에 대한 설명으로 가장 옳지 않은 것은?
- FIFO 기법에서는 아무리 참조가 많이 된 페이지라도 교체될 수 있다.
- LRU 기법을 위해서는 적재된 페이지들의 참조된 시간 또는 순서에 대한 정보가 필요하다.
- Second-chance 기법에서는 참조 비트가 0인 페이지는 교체되지 않는다.
- LFU 기법은 많이 참조된 페이지는 앞으로도 참조될 확률이 높을 것이란 판단에 근거한 기법이다.
6. 네트워킹 장비에 대한 설명으로 가장 옳지 않은 것은?
- 라우터(router)는 데이터 전송을 위한 최선의 경로를 결정한다.
- 허브(hub)는 전달받은 신호를 그와 케이블로 연결된 모든 노드들에 전달한다.
- 스위치(switch)는 보안(security) 및 트래픽(traffic) 관리 기능도 제공할 수 있다.
- 브리지(bridge)는 한 네트워크 세그먼트에서 들어온 데이터를 그의 물리적 주소에 관계없이 무조건 다른 세그먼트로 전달한다.
7. 다음의 정렬된 데이터에서 2진탐색을 수행하여 C를 찾으려고 한다. 몇 번의 비교를 거쳐야 C를 찾을 수 있는가? (단, 비교는 ‘크다’, ‘작다’, ‘같다’ 중의 하나로 수행되고, ‘같다’가 도출될 때까지 반복된다.)
- 1번
- 2번
- 3번
- 4번
8. 인터넷 서비스 관련 용어들에 대한 설명으로 가장 옳지 않은 것은?
- ASP는 동적 맞춤형 웹페이지의 구현을 위해 사용된다.
- URL은 인터넷상에서 문서나 파일의 위치를 나타낸다.
- HTML은 웹문서의 전달을 위한 통신 규약이다.
- SSL은 안전한 웹통신을 위한 암호화를 위해 사용된다.
9. <보기>의 배열 A에 n개의 원소가 있다고 가정하자. 다음 의사코드에 대한 설명으로 가장 옳지 않은 것은?
- 제일 큰 원소를 끝자리로 옮기는 작업을 반복한다.
- 선택 정렬을 설명하는 의사코드이다.
- O(n2)의 수행 시간을 가진다.
- 두 번째 for 루프의 역할은 가장 큰 원소를 맨 오른쪽으로 보내는 것이다.
10. <보기>의 Java 프로그램의 실행 결과는?
- 3 2
- 3 4
- 1 2
- 1 4
11. 어떤 시스템은 7비트의 데이터에 홀수 패리티 비트를 최상위 비트에 추가하여 8비트로 표현하여 저장한다. 다음과 같은 데이터를 저장 장치에서 읽어 왔을 때 오류가 발생한 경우는?
- 011010111
- 101101111
- 011001110
- 101001101
12. 고객, 제품, 주문, 배송업체 테이블을 가진 판매 데이터 베이스를 SQL을 이용해 구축하고자 한다. 각 테이블이 <보기>와 같은 속성을 가진다고 가정할 때, 다음 중 가장 옳지 않은 SQL문은? (단, 밑줄은 기본키를 의미한다.)
- 고객 테이블에 가입 날짜를 추가한다.→ “ALTER TABLE 고객 ADD 가입 날짜 DATE;”
- 주문 테이블에서 배송지를 삭제한다.→ “ALTER TABLE 주문 DROP COLUMN 배송지”
- 고객 테이블에 18세 이상의 고객만 가입 가능하다는 무결성 제약 조건을 추가한다. → “ALTER TABLE 고객 ADD CONSTRAINT CHK_AGE CHECK(나이>=18)”
- 배송업체 테이블을 삭제한다.→ “ALTER TABLE 배송업체 DROP”
13. <보기>의 UML 다이어그램 중 시스템의 구조(structure) 보다는 주로 동작(behavior)을 묘사하는 다이어그램들만 고른 것은?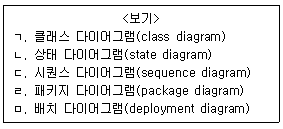
- ㄱ, ㄹ
- ㄴ, ㄷ
- ㄴ, ㅁ
- ㄷ, ㄹ
14. <보기 1>의 테이블 R에 대해 <보기 2>의 SQL을 수행한 결과로 옳은 것은?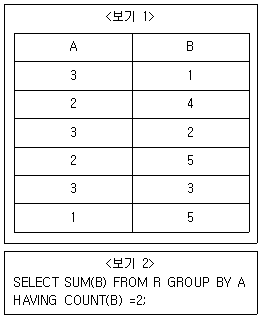
- 2
- 5
- 6
- 9
15. <보기>는 데이터가 정렬되는 단계를 일부 보여준 것이다. 어떤 정렬 알고리즘을 사용하면 이와 같은 데이터의 자리 교환이 일어나겠는가? (단, 제일 위의 행이 주어진 데이터이고, 아래로 내려갈수록 정렬이 진행되는 것이다.)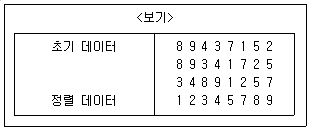
- 삽입 정렬
- 선택 정렬
- 합병 정렬
- 퀵 정렬
 의 정렬 과정을 보면, 데이터를 작은 단위로 쪼갠 뒤 다시 합치면서 정렬하는 분할 정복(Divide and Conquer) 방식의 특징이 나타납니다. 이는 데이터를 반으로 나누어 각각 정렬한 후 병합하는 합병 정렬의 전형적인 동작 과정입니다.
의 정렬 과정을 보면, 데이터를 작은 단위로 쪼갠 뒤 다시 합치면서 정렬하는 분할 정복(Divide and Conquer) 방식의 특징이 나타납니다. 이는 데이터를 반으로 나누어 각각 정렬한 후 병합하는 합병 정렬의 전형적인 동작 과정입니다.
16. <보기>의 각 설명과 일치하는 데이터 구조로 바르게 짝지어진 것은? (순서대로 ㈎, ㈏, ㈐)
- 큐, 연결 리스트, 스택
- 스택, 연결 리스트, 큐
- 스택, 큐, 연결 리스트
- 큐, 스택, 연결 리스트
17. 전화번호의 마지막 네 자리를 3으로 나눈 나머지를 해싱(hashing)하여 데이터베이스에 저장하고자 한다. 나머지 셋과 다른 저장 장소에 저장되는 것은?
- 010-4021-6718
- 010-9615-4815
- 010-7290-6027
- 010-2851-5232
18. 다음 메모리 영역 중 전역 변수가 저장되는 영역은?
- 데이터(Data)
- 스택(Stack)
- 텍스트(Text)
- 힙(Heap)
19. UML(Unified Modeling Language)에 대한 설명으로 가장 옳지 않은 것은?
- UML은 방법론으로, 단계별로 어떻게 작업해야 하는지 자세하게 나타낸다.
- UML은 소프트웨어의 구성요소와 그것들의 관계 및 상호작용을 시각화한 것이다.
- UML은 객체지향 소프트웨어를 모델링하는 표준 그래픽 언어로, 심벌과 그림을 사용해 객체지향 개념을 나타낼 수 있다.
- UML은 소프트웨어 개발의 중요한 작업인 분석, 설계, 구현의 정확하고 완벽한 모델을 제공한다.
20. <보기>의 C 프로그램을 실행했을 때, 화면에 출력되는 값은? (단, 프로그램의 첫 번째 열의 숫자는 행 번호이고 프로그램의 일부는 아님.)
- 0
- 3
- 6
- 12
전처리기(preprocessor) $\rightarrow$ 컴파일러(compiler) $\rightarrow$ 어셈블러(assembler) $\rightarrow$ 링커(linker) $\rightarrow$로더(loader) 순으로 진행되므로, 3번째로 실행되는 단계는 어셈블러(assembler)입니다.