1과목: 데이터 베이스
1. 뷰(VIEW)에 대한 설명으로 옳지 않은 것은?
- 삽입, 삭제, 갱신 연산의 용이
- 데이터의 논리적 독립성 유지
- 데이터 접근 제어에 의한 보안 제공
- 사용자의 데이터 관리 용이






2. 다음 자료를 삽입 정렬을 이용하여 오름차순으로 정렬할 경우 “pass 5"의 결과는?
- 14, 15, 27, 32, 38, 6, 21
- 14, 15, 32, 38, 27, 6, 21
- 6, 14, 15, 27, 32, 38, 21
- 6, 14, 15, 21, 27, 32, 38

3. 다음 영문의 ①, ② 에 적합한 내용으로 짝지어진 것은?
- ① Queue ② Stack
- ① Stack ② Queue
- ① Tree ② Stack
- ① Stack ② Tree
 의 빈칸에 들어갈 내용은 순서대로 Stack과 Queue입니다.
의 빈칸에 들어갈 내용은 순서대로 Stack과 Queue입니다.
4. 관계 대수와 관계 해석에 대한 설명으로 옳지 않은 것은?
- 관계 대수는 원래 수학의 프레디킷 해석에 기반을 두고 있다.
- 관계 대수로 표현한 식은 관계 해석으로 표현할 수 있다.
- 관계 해석은 관계 데이터의 연산을 표현하는 방법이다.
- 관계 해석은 원하는 정보가 무엇이라는 것만 정의하는 비절차적인 특징을 가지고 있다.
5. 다음 문장의 ( )에 적당한 것은?
- block
- tuple
- field
- file
6. 트랜잭션의 특성 중 다음 설명에 해당하는 것은?
- Atomicity
- Isolation
- Consistency
- Durability
7. A, B, C, D의 순서로 정해진 입력 자료를 스택에 입력하였다가 출력한 결과가 될 수 없는 것은? (단, 왼쪽부터 먼저 출력된 순서이다. )
- A, D, B, C
- A, B, C, D
- D, C, B, A
- B, C, D, A
8. 데이터베이스 설계 순서를 바르게 나열한 것은?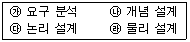
- 가 → 나 → 다 → 라
- 가 → 다 → 나 → 라
- 다 → 나 → 라 → 가
- 다 → 라 → 나 → 가

9. 데이터 모델의 구성 요소가 아닌 것은?
- 데이터구조(structure)
- 연산(operations)
- 관계(relationship)
- 제약조건(constraints)
10. 해싱 함수의 값을 구한 결과 키 K1, K2 가 같은 값을 가질 때, 이들 키 K1, K2 의 집합을 무엇이라고 하는가?
- Mapping
- Folding
- Synonym
- Chaining
11. 릴레이션의 특징으로 옳지 않은 것은?
- 모든 튜플은 서로 다른 값을 갖는다.
- 각 속성은 릴레이션 내에서 유일한 이름을 갖는다.
- 하나의 릴레이션에서 튜플의 순서는 없다.
- 릴레이션에 나타난 속성 값은 분해가 가능해야 한다.
12. 릴레이션 A는 4개의 튜플로 구성되어 있고, 릴레이션 B는 6개의 튜플로 구성되어 있다. 두 릴레이션에 대한 카티션 프로덕트 연산의 결과로서 몇 개의 튜플이 생성되는가?
- 2
- 6
- 10
- 24
13. 스택에서의 삽입 알고리즘으로 빈칸에 들어갈 내용은?
- STACK[TOP] = new node
- STACK[TOP + 1 ] = new node
- TOP = N
- TOP = TOP + 1
14. 다음의 전위(prefix) 표기식을 중위(Infix) 표기식으로 옳게 변환한 것은?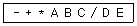
- B * D + A - E / C
- C * D + B - A / E
- E * D + C - B / A
- A * B + C - D / E
15. 학생(STUDENT) 테이블에서 어떤 학과(DEPT)들이 있는지 검색하는 SQL 명령은? (단, 결과는 중복된 데이터가 없도록 한다.)
- SELECT ONLY * FROM STUDENT;
- SELECT DISTINCT DEPT FROM STUDENT;
- SELECT ONLY DEPT FROM STUDENT;
- SELECT NOT DUPLICATE DEPT FROM STUDENT;
16. 다음 트리를 Post-order로 운행할 때 노드 D는 몇 번째로 검사되는가?
- 1
- 2
- 3
- 4

17. 데이터베이스 설계 단계 중 논리적 설계 단계에서의 수행사항이 아닌 것은?
- 논리적 데이터 모델로 변환
- 트랜잭션 인터페이스 설계
- 저장 레코드 양식 설계
- 스키마의 평가 및 정제
18. 데이터베이스의 특징이 아닌 것은?
- 실시간 접근성(real-time accessibility)
- 계속적인 변화(continuous evolution)
- 동시 공유(concurrent sharing)
- 번호에 의한 참조(numbering reference)
19. DBMS에 대한 설명으로 옳지 않은 것은?
- 예비와 회복 기법의 단순화
- 데이터 중복의 최소화
- 데이터의 무결성 유지
- 데이터의 공유
20. 시스템 카탈로그에 대한 설명으로 옳지 않은 것은?
- 시스템 자신이 필요로 하는 스키마 및 여러 가지 객체에 관한 정보를 포함하고 있는 시스템 데이터베이스이다.
- 시스템 카탈로그에 저장되는 내용을 메타데이터라고 한다.
- 데이터 사전이라고도 한다.
- 일반 사용자는 시스템 테이블의 내용을 검색할 수 없다.
2과목: 전자 계산기 구조
21. 다음 그림에서 출력 F가 갖는 논리값은?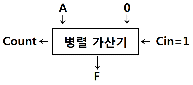
- F = A-1
- F = A+1
- F = A
- F = A'
22. 데이터 단위가 8비트인 메모리에서 용량이 8192byte인 경우 어드레스 핀의 개수는?
- 12개
- 13개
- 14개
- 15개
23. 일반적인 컴퓨터의 명령어 형식에 포함되지 않은 필드(field)는?
- 연산코드 필드
- 주소 모드 필드
- 주소 필드
- 분기 필드
24. 중앙처리장치의 정보를 기억장치에 기억시키는 것은?
- LOAD
- BRANCH
- TRACE
- STORE
25. 하드웨어의 특성상 주기억장치가 제공할 수 있는 정보전달의 능력 한계는?
- 주기억장치 전달폭
- 주기억장치 용량폭
- 주기억장치 접근폭
- 주기억장치 대역폭
26. 레지스터와 레지스터 사이에서의 데이터 전송 방법을 설명한 것 중 틀린 것은?
- 레지스터간의 전송은 직렬 전송, 병렬 전송, 버스전송으로 크게 구분할 수 있다.
- 보통 직렬 전송은 직렬 시프트 마이크로 오퍼레이션(serial shift micro operation)을 뜻하며, 병렬전송에 비해 전송 속도가 빠르다.
- 병렬 전송은 하나의 클록 펄스 동안에 레지스터 내의 모든 비트 즉, 워드가 동시에 전송되는 방식이다.
- 버스 전송은 병렬 전송에 비해 결선의 수를 줄일 수 있다는 장점을 가지고 있다.
27. 제어장치의 구현방법 중 고정 배선식 제어장치(Hard Wired Control Unit)에 대한 설명으로 틀린 것은?
- 하드웨어적으로 구현한 방법으로 제어신호를 발생시킨다.
- 마이크로프로그램 제어방식보다 속도가 빠르다.
- 한 번 만들어진 명령어 세트를 변경할 수 없다.
- 제작은 어렵지만 제작비용은 저렴하다.
28. interrupt를 발생하는 모든 장치들을 직렬로 연결하여 우선순위를 결정하는 방식은?
- step by step 방식
- serial encoder 방식
- interrupt register 방식
- daisy-chain 방식
29. 상대 주소 지정 방식(relative addressing mode)에 가장 많이 쓰이는 명령어는?
- 분기 명령어
- 전달 명령어
- 감산 명령어
- 입출력 명령어
30. 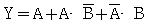 의 논리식을 간단히 하면?
의 논리식을 간단히 하면?
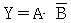

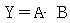
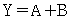
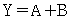 입니다.
입니다.
31. 채널(channel)을 설명한 것으로 틀린 것은?
- I/O 속도를 향상시킨다.
- 고속 방식과 저속 방식의 채널이 있다.
- CPU의 idle time을 줄인다.
- MODEM의 기능을 갖는다.
32. 캐시(cache)에 기억시키는 블록 주소의 일부는?
- 태그주소
- 묵시주소
- 캐시주소
- 유효주소
33. 롬(ROM)내에 기억시켜 둘 필요가 없는 정보는?
- 부트스트랩 로더(bootstrap loader)
- 마이크로프로그램(micro program)
- 디스플레이 문자 코드(display character code)
- 소스 프로그램(source program)
34. 주소 지정 방식 중 오퍼랜드를 Fetch하는데 가장 많이 메모리를 접근하는 방식은?
- 레지스터 주소(register addressing) 방식
- 직접 주소(direct addressing) 방식
- 간접 주소(indirect addressing) 방식
- 즉시 주소(immediate addressing) 방식
35. 컴퓨터에서 MAR(Memory Address Register)의 역할은?
- 수행되어야 할 프로그램의 주소를 가리킨다.
- 메모리에 보관된 내용을 누산기(accumulator)에 전달하는 역할을 한다.
- 고급 수준 언어를 기계어로 변환해 주는 일종의 소프트웨어이다.
- CPU에서 기억장치내의 특정번지에 있는 데이터나 명령어를 인출하기 위해 그 번지를 기억하는 역할을 한다.
36. 명령어의 주소 부분에 실제 사용할 데이터의 유효주소(effective address)를 저장하고 주소 길이에 제약을 받는 주소 지정 방식은?
- 즉시 주소 방식
- 직접 주소 방식
- 간접 주소 방식
- 인덱스 레지스터 주소 방식
37. 중앙처리장치가 인터럽트 요청을 받았을 때의 처리순서를 옳게 나타낸 것은?
- ④→③→②→①
- ②→①→④→③
- ②→①→③→④
- ④→②→①→③
 (②)
(②)
38. 마이크로 사이클 중 동기 고정식에 비교하여 동기 가변식에 관한 설명으로 틀린 것은?
- CPU의 시간을 효율적으로 이용
- 마이크로 오퍼레이션 수행 시간의 차이가 클 경우 사용
- 마이크로 오퍼레이션의 수행 시간이 유사한 경우 사용
- 그룹화된 각 마이크로 오퍼레이션들에 대하여 서로 다른 사이클을 정의
39. 주기억 장치에 기억된 명령을 꺼내서 해독하고, 시스템 전체에 지시 신호를 내는 것은?
- 채널(channel)
- 제어장치(control unit)
- 연산논리장치(ALU)
- 입출력장치(I/O unit)
40. 패리티 비트(parity bit)를 부가하여 사용하기에 가장 적절한 것은?
- ASCII 코드
- BCD 코드
- EBCDIC 코드
- 7421 코드
3과목: 시스템분석설계
41. 자료 흐름도(DFD)에 대한 설명으로 옳지 않은 것은?
- 하향식 분할 원리를 적용하여 그림 중심으로 표현한다.
- 자료 저장소는 직사각형으로 표시한다.
- 개발 대상 업무의 작업 흐름을 쉽게 이해할 수 있다.
- 사용자의 요구 사항을 정확하게 파악할 수 있다.
42. 출력정보의 설계 순서가 올바른 것은?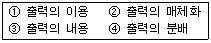
- ①→②→③→④
- ①→③→②→④
- ③→②→④→①
- ②→④→①→③
 이미지의 순서는 출력의 내용 $\rightarrow$ 출력의 매체화 $\rightarrow$ 출력의 분배 $\rightarrow$ 출력의 이용 순이 정답입니다.
이미지의 순서는 출력의 내용 $\rightarrow$ 출력의 매체화 $\rightarrow$ 출력의 분배 $\rightarrow$ 출력의 이용 순이 정답입니다.
43. 문서화(Documentation)의 목적에 대한 설명으로 거리가 먼 것은?
- 시스템 개발 중 추가 변경에 따른 혼란 방지
- 개발 후 시스템 유지 보수의 용이
- 시스템의 개발 요령과 순서를 표준화하여 보다 효율적인 작업 도모
- 시스템 개발의 요식 행위화
44. 출력 시스템과 입력 시스템이 일치된 것으로 일단 출력된 정보가 이용자의 손을 거쳐 다시 입력되는 시스템의 형태는?
- Display 출력 시스템
- Turn Around 시스템
- File 출력 시스템
- COM(Computer Output Microfilm) 시스템
45. 파일 설계 단계 중 파일 매체 검토시 고려사항이 아닌 것은?
- 파일 활동률
- 작동 용이성
- 정보량
- 처리 시간
46. 객체지향 기법에 대한 설명으로 옳지 않은 것은?
- 복잡한 구조를 단계적, 계층적으로 표현할 수 있다.
- 구조적 기법의 문제점으로 인한 소프트웨어 위기의 해결책으로 채택되어 사용되고 있다.
- 소프트웨어 개발 및 유지보수가 용이하다.
- 상속을 통한 재사용과 시스템 확장은 용이하지 않다.
47. 체크 시스템 중 계산단계에서 마스터 파일과 트랜잭션 파일을 조합할 때 키 항목이 일치하는지의 여부를 검사하는 오류검사 방법은?
- 공란 검사
- 불일치 레코드 검사
- 타당성 검사
- 대조 검사
48. 시스템의 기본 요소와 관련 없는 것은?
- 입력
- 출력
- 처리
- 평가
49. 코드설계 순서로 옳은 것은?
- ⑦→③→②→⑤→⑥→①→④
- ⑦→③→⑤→②→⑥→①→④
- ③→②→⑦→⑤→⑥→①→④
- ⑦→①→②→⑤→⑥→③→④
50. 시스템의 특징 중 다음 설명에 해당하는 것은?
- 자동성
- 종합성
- 목적성
- 제어성
 의 '이탈되는 사태나 현상의 발생을 사전에 감지하여 그것을 바르게 수정해 가는 것'은 시스템의 제어성을 의미합니다.
의 '이탈되는 사태나 현상의 발생을 사전에 감지하여 그것을 바르게 수정해 가는 것'은 시스템의 제어성을 의미합니다.
51. 프로세스 입력단계에서의 체크 중 입력정보의 특정 항목 합계 값을 미리 계산해서 이것을 입력정보와 함께 입력하고 컴퓨터상에서 계산한 결과와 수동 계산 결과가 같은지를 체크하는 것은?
- 순차 체크(sequence check)
- 공란 체크(blank check)
- 형식 체크(format check)
- 일괄 합계 체크(batch total check)
52. 한 모듈이 다른 모듈의 내부 자료를 직접적으로 참조하는 경우의 결합도를 의미하는 것은?
- 내용 결합도
- 공통 결합도
- 제어 결합도
- 스탬프 결합도
53. 시스템 평가(System test)의 종류 중 다음 항목과 관계 되는 것은?
- 가격평가
- 기능 평가
- 성능평가
- 신뢰성 평가
 내용 중 '오류 없이 작동할 확률', '가동률', 'MTBF(평균 고장 간격)' 측정은 시스템의 안정성과 신뢰도를 평가하는 신뢰성 평가의 핵심 지표입니다.
내용 중 '오류 없이 작동할 확률', '가동률', 'MTBF(평균 고장 간격)' 측정은 시스템의 안정성과 신뢰도를 평가하는 신뢰성 평가의 핵심 지표입니다.
54. 마스터 파일 내의 데이터를 트랜잭션 파일로 추가, 정정, 삭제하여 항상 최근의 정보를 갖도록 하는 것을 무엇이라 하는가?
- 정렬(sort)
- 갱신(update)
- 병합(merge)
- 대조(matching)
55. 특정 모듈에 대해서 존재하는 처리 요소들 간의 기능적 연관성을 의미하는 것으로 입력이나 에러 처리 같은 유사한 기능을 행하는 요소끼리 하나의 요소로 묶는 응집도는?
- 기능적 응집도
- 순차적 응집도
- 논리적 응집도
- 절차적 응집도
56. 파일 설계 순서로 옳은 것은?
- ①→②→③→④
- ②→③→①→④
- ①→③→②→④
- ④→③→②→①
57. 프로세스 설계상 유의 사항으로 거리가 먼 것은?
- 프로세스 전개의 사상을 통일한다.
- 하드웨어의 기기 구성, 처리 성능을 고려한다.
- 운영체제를 중심으로 한 소프트웨어의 효율성을 고려한다.
- 오류에 대비한 체크 시스템의 고려는 필요 없으며, 분류 처리를 가능한 최대화한다.
58. 코드화의 기능이 아닌 것은?
- 오류검출 및 정정기능
- 암호화 기능
- 표준화 기능
- 분류 및 식별 기능
59. 코드 설계시 유의사항으로 옳지 않은 것은?
- 공통성과 체계성이 있어야 한다.
- 대상 자료와 일 대 다(1:N) 대응되도록 설계한다.
- 사용자가 취급하기 쉬워야 한다.
- 컴퓨터 처리에 적합해야 한다.
60. 입력 설계 단계 중 입력정보 매체화 설계시 고려사항이 아닌 것은?
- 매체화 담당자 및 장소
- 레코드 길이 및 형식
- 입력 항목의 배열순서 및 항목명
- 매체화시의 오류체크방법
4과목: 운영체제
61. 16개의 CPU로 구성된 하이퍼큐브에서 각 CPU는 몇 개의 연결점을 갖는가?
- 2
- 4
- 128
- 256
62. 상호배제의 문제는 병행하여 처리되는 여러 개의 프로세스가 공유 자원을 동시에 접근하기 때문에 발생한다. 따라서 공유되는 자원에 대한 처리 내용 중에서 상호배제를 시켜야 하는 일정 부분에 대해서는 어느 하나의 프로세스가 처리하는 동안에 다른 프로세스의 접근을 허용하지 말아야 한다. 이 때, 상호배제를 시켜야 하는 일정 부분을 무엇이라고 하는가?
- Locality
- Page
- Semaphore
- Critical Section
63. 교착상태의 해결 방안 중 교착상태의 발생 가능성을 배제하지 않고 이를 적절하게 피해 나가는 방법을 의미하는 것은?
- Prevention
- Detection
- Avoidance
- Recovery
64. 운영체제에 대한 설명으로 옳지 않은 것은?
- CPU, 메모리 공간, 기억 장치, 입출력 장치, 정보관리 등의 자원을 관리한다.
- 다중 사용자와 다중 응용프로그램 환경 하에서 자원의 현재 상태를 파악하고 자원 분배를 위한 스케줄링을 담당한다.
- 사용자가 컴퓨터 하드웨어를 사용하기 쉽도록 컴퓨터와 사용자간의 인터페이스를 지원한다.
- 운영체제의 운용기법 중 일괄처리시스템은 라운드로빈 방식이라고도 한다.
65. UNIX에서 사용하는 디렉토리 구조는?
- 단일 구조
- 일반적 그래프 구조
- 비순환 그래프 구조
- 트리 구조
66. 페이지 교체 기법 중 시간 오버헤드를 줄이는 기법으로서 참조 비트(Referenced bit)와 변형 비트(Modified bit)를 필요로 하는 방법은?
- FIFO
- LRU
- LFU
- NUR
67. SJF(Shortest job First) 스케줄링에서 작업 도착 시간과 CPU 사용시간은 다음 표와 같다. 모든 작업들의 평균 대기시간은 얼마인가?
- 15
- 16
- 24
- 25
68. 다음과 같이 트랙이 요청되어 큐에 순서적으로 도착하였다. 현재 헤드의 위치는 트랙 50 이며, 모든 트랙을 서비스하기 위하여 디스크 스케줄링 기법 중 FCFS 스케줄링 기법이 사용되었을 경우, 트랙 35는 요청된 트랙 중 몇 번째에 서비스를 받게 되는가? (단, 가장 안쪽 트랙은 0 이다.)
- 1번째
- 2번째
- 3번째
- 4번째
 에 제시된 요청 순서는 10 $\rightarrow$ 40 $\rightarrow$ 55 $\rightarrow$ 35 순이므로, 트랙 35는 4번째로 서비스를 받게 됩니다.
에 제시된 요청 순서는 10 $\rightarrow$ 40 $\rightarrow$ 55 $\rightarrow$ 35 순이므로, 트랙 35는 4번째로 서비스를 받게 됩니다.
69. 주기억장치 관리기법 중 “Best Fit” 기법 사용시 20K의 프로그램은 주기억장치 영역 번호 중 어느 곳에 할당되는가?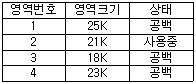
- 영역 번호 1
- 영역 번호 2
- 영역 번호 3
- 영역 번호 4
70. 파일 시스템의 기능으로 거리가 먼 것은?
- 여러 종류의 접근 제어 방법 제공
- 파일의 생성, 변경, 제거
- 네트워크 제어
- 파일의 무결성과 보안을 유지할 수 있는 방안 제공
71. 분산처리 운영 시스템에 대한 설명으로 옳지 않은 것은?
- 사용자는 각 컴퓨터의 위치를 몰라도 자원 사용이 가능하다.
- 시스템의 점진적 확장이 용이하다.
- 중앙 집중형 시스템에 비해 시스템 설계가 간단하고 소프트웨어 개발이 쉽다.
- 연산속도, 신뢰성 사용 가능도가 향상된다.
72. HRN 스케줄링 기법을 적용할 경우 우선순위가 가장 낮은 것은?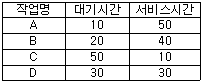
- A
- B
- C
- D
73. 라운드로빈(Round-Robin) 방식으로 스케줄링 할 경우, 입력된 작업이 다음과 같고 각 작업의 CPU 할당시간이 4시간일 때, 모든 작업을 완료하기 위한 CPU의 사용 순서가 옳게 나열된 것은?
- A B C A B C B C C
- A B C A B C A C A
- A B C A B C B C C C
- A C C C C C B
74. 4 개의 페이지를 수용할 수 있는 주기억장치가 현재 완전히 비어 있으며, 어떤 프로세스가 다음과 같은 순서로 페이지번호를 요청했을 때 페이지 대체 정책으로 FIFO를 사용한다면 페이지 부재(Page-fault)의 발생 횟수는?
- 3회
- 4회
- 5회
- 6회
75. 파일 디스크립터(File Descriptor)에 대한 설명으로 옳지 않은 것은?
- 파일이 액세스되는 동안 운영체제가 관리 목적으로 알아야 할 정보를 모아 놓은 자료 구조이다.
- 파일 디스크립터는 모든 시스템에 공통적인 구조를 가진다.
- 사용자가 직접 참조할 수 없다.
- 해당 파일이 Open되면 FCB가 메모리에 옮겨진다.
76. 디렉토리 구조 중 중앙에 마스터 파일 디렉토리가 있고, 그 아래에 사용자별로 서로 다른 파일 디렉토리가 있는 구조는?
- 1단계 디렉토리 구조
- 2단계 디렉토리 구조
- 비순환 그래프 디렉토리 구조
- 일반적 그래프 디렉토리 구조
77. 구역성(Locality)에 대한 설명으로 옳지 않은 것은?
- 프로세스가 실행되는 동안 일부 페이지만 집중적으로 참조되는 경향을 말한다.
- 시간 구역성은 최근에 참조된 기억장소가 가까운 장래에도 계속 참조될 가능성이 높음을 의미한다.
- 공간 구역성은 하나의 기억장소가 참조되면 그 근처의 기억장소가 계속 참조되는 경향이 있음을 의미한다.
- 프로세스가 효율적으로 실행되기 위해 프로세스에 의해 자주 참조되는 페이지들의 집합을 말한다.
78. 운영체제의 목적으로 옳지 않은 것은?
- 사용가능도 향상, 반환시간 증가, 신뢰도 향상
- 사용자와 컴퓨터 간의 인터페이스 제공
- 데이터 공유 및 주변장치 관리
- 자원의 효율적인 운영 및 자원 스케줄링
79. UNIX에서 현재 디렉토리 내의 파일 목록을 확인하는 명령은?
- find
- ls
- cat
- finger
80. 프로세스(Process)의 정의와 거리가 먼 것은?
- PCB의 존재로서 명시되는 것
- 동기적 행위를 일으키는 주체
- 프로시저가 활동 중인 것
- 실행중인 프로그램
5과목: 정보통신개론
81. 다음이 설명하고 있는 것은?
- 집중화
- 암호화
- 복호화
- 다중화

82. X .25 프로토콜을 구성하는 계층에 해당하지 않는 것은?
- 패킷 계층
- 물리 계층
- 링크 계층
- 응용 계층
83. 비동기식 전송방식의 특징으로 틀린 것은?
- 한 번에 한 문자씩 전송되는 방식이다.
- 300~19200[bps]의 비교적 저속의 데이터 전송에 주로 이용된다.
- 문자단위의 재 동기를 위해 시작비트(Start bit)와 정지(Stop bit)비트를 둔다.
- 송수신기의 클록 오차에 의한 오류를 줄이기 위해 긴 비트열을 전송하여 타이밍 오류를 피한다.
84. 호스트 A에서 사용하는 데이터 형식은 ASCII이고 호스트 B에서 사용하는 데이터 형식은 EBCDIC 인 경우에 두 호스트간의 통신을 가능하게 하기 위해서는 데이터 형식간의 변환 기능이 요구된다. 이러한 기능은 OSI 7계층 중 어느 계층에서 수행되는가?
- 물리 계층
- 데이터링크 계층
- 세션 계층
- 표현 계층
85. DTE에서 발생하는 NRZ-L 형태의 디지털 신호를 다른 형태의 디지털 신호로 바꾸어 먼 거리까지 전송이 가능하도록 하는 것은?
- DCE
- RTS
- DSU
- CTS
86. OSI 7계층 중 응용간의 대화 제어(dialogue control)를 담당하는 것은?
- 네트워크 계층
- 응용 계층
- 세션 계층
- 데이터링크 계층
87. IEEE 802 시리즈의 표준화 모델이 바르게 연결된 것은?
- IEEE 802.2 - 매체접근 제어(MAC)
- IEEE 802.3 - 광섬유 LAN
- IEEE 802.4 - 토큰 버스(Token Bus)
- IEEE 802.5 - 논리링크 제어(LLC)
88. 변조방식 중 ASK 변조란 어떤 변조방식인가?
- 전송편이 변조
- 주파수편이 변조
- 위상편이 변조
- 진폭편이 변조
89. 여러 개의 터미널 신호를 하나의 통신회선을 통해 전송 할 수 있도록 하는 장치는?
- 변복조장치
- 멀티플렉서
- 전자교환기
- 디멀티플렉서
90. 정보통신시스템의 기본적인 구성 중 이용자와 정보통신시스템과의 접점에서 데이터의 입출력을 담당하는 것은?
- 단말장치
- 정보처리시스템
- 데이터전송회선
- 변복조장치
91. OSI 7계층 모델에서 기계적, 전기적, 절차적 특성을 정의한 계층은?
- 전송 계층
- 데이터링크 계층
- 물리 계층
- 표현 계층
92. LAN의 토폴로지 형태에 해당하지 않는 것은?
- Star형
- Bus형
- Ring형
- Square형
93. 디지털 데이터를 아날로그 신호로 변환하는 과정에서 두 개의 2진 값이 서로 다른 두 개의 주파수로 구분되는 변조 방식은?
- ASK
- FSK
- PSK
- QPSK
94. TCP/IP 프로토콜 구조 중 응용 계층에서 동작하지 않는 것은?
- FTP
- Telnet
- SMTP
- ICMP
95. 에러 제어 방식 중 CRC(Cyclic Redundancy Check)에 대한 설명으로 옳은 것은?
- 한 블록의 데이터 끝에 하나의 비트를 추가하여 에러를 검출하는 방법이다.
- 에러 검출뿐만 아니라 에러 정정까지도 가능한 방법이다.
- 프레임 단위로 오류 검출을 위한 코드를 계산하여 프레임 끝에 부착하는데 이를 “FCS"라 한다.
- 에러 검출을 위해 해밍코드(Hamming code)를 사용한다.
96. 다음이 설명하고 있는 LAN의 매체 접근 제어방식은?
- CSMA/CD
- token bus
- token ring
- slotted ring
 의 설명은 CSMA/CD 방식에 대한 것입니다.
의 설명은 CSMA/CD 방식에 대한 것입니다.
97. 정보통신시스템의 구성 요소에 대한 설명으로 거리가 먼 것은?
- CCU, FEP는 통신 제어 장치이다.
- MODEM은 변복조 장치이다.
- DTE는 데이터 에러 감시 장치이다.
- DSU는 신호 변환 장치이다.
98. ATM 교환기에서 처리되는 셀의 길이는?
- 24바이트
- 48바이트
- 53바이트
- 64바이트
99. HDLC(High-Level Data Link Control)에 대한 설명으로 옳지 않은 것은?
- 비트지향형의 프로토콜이다.
- 링크 구성 방식에 따라 세 가지 동작모드를 가지고 있다.
- 데이터링크 계층의 프로토콜이다.
- 반이중과 전이중 통신이 불가능하다.
100. 화상정보가 축적된 정보센터의 데이터베이스를 TV수신기와 공중전화망에 연결해서 이용자가 화면을 보면서 상호대화 형태로 각종 정보검색을 할 수 있는 것은?
- Teletext
- Videotex
- HDTV
- CATV