1과목: 시스템 프로그래밍
1. 로더의 기능이 아닌 것은?
- 할당(allocation)
- 번역(translation)
- 링킹(linking)
- 로딩(loading)






2. 매크로 프로세서를 어셈블러의 패스1에 통합시킬 경우의 장점을 나열한 것으로 가장 옳지 못한 것은?
- 매크로가 어셈블러의 패스1내에 포함됨으로써 중간 파일들이 생성된다.
- 공통된 기능을 양쪽에서 가질 필요가 없다.
- 처리 도중에 부담이 줄어든다.
- 프로그래머 입장에서 매크로와 연결하여 어셈블러의 모든 기능을 함께 사용할 수 있어 작업이 쉬워진다.
3. 프로세서들 사이에 우선순위를 두지 않고 시간단위(Time Quantum)로 CPU를 할당하는 스케줄링 방식은?
- FIFO
- RR
- SJF
- HRN
4. 운영체제를 기능별로 분류할 경우 제어 프로그램에 해당하지 않는 것은?
- 감시 프로그램
- 문제 프로그램
- 작업 제어 프로그램
- 자료 관리 프로그램
5. 다음 중 링킹(linking) 작업의 결과는?
- 원시 모듈을 생성한다.
- 외부 모듈을 생성한다.
- 목적 모듈을 생성한다.
- 적재 모듈을 생성한다.
6. 어셈블리어에서 의사 명령에 해당하는 것은?
- USING
- SR
- AR
- ST
7. 기억장치 관리 전략에서 배치 전략의 종류 중 다음 설명에 해당하는 것은?
- Worst Fit
- Best Fit
- First Fit
- Last Fit

8. 어셈블리어에서 어떤 기호적 이름에 상수값을 할당하는 명령은?
- EQU
- ASSUME
- ORG
- EVEN
9. 3개의 페이지 프레임을 갖는 시스템에서 페이지 참조 순서가 아래와 같다. FIFO 페이지 대치 알고리즘을 적용할 때 페이지 부재와 발생하는 총 횟수는?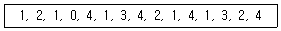
- 10
- 12
- 13
- 15
10. 절대로더(absolute loader)를 이용할 경우 어셈블러에 의해 처리되는 것은?
- 기억 장소 할당(allocation)
- 재배치(relocation)
- 연결(linking)
- 적재(loading)
11. 다음 중 비선점(non-preemptive) 스케줄링 기법의 특징으로 옳은 것은?
- 프로세서 응답시간의 예측이 용이하여, 일괄처리 방식에 적합하다.
- 우선순위가 높은 프로세서를 빨리 처리할 수 있다.
- 많은 오버헤드(Overhead)를 초래한다.
- 주로 빠른 응답시간이 요구되는 대화식 시분할시스템, 온라인 응용에 사용된다.
12. 프로세서들이 서로 작업을 진행하지 못하고 영원히 대기상태로 빠지게 되는 현상을 무엇이라고 하는가?
- thrashing
- working set
- semaphore
- deadlock
13. 교착상태의 해결 방법 중 은행원 알고리즘과 관계되는 것은?
- 예방 기법
- 회피 기법
- 발견 기법
- 회복 기법
14. 기계어에 대한 설명으로 옳지 않은 것은?
- 컴퓨터가 직접 이해할 수 있는 언어이다.
- 기종마다 기계어가 다르므로 언어의 호환성이 없다.
- 0과 1의 2진수 형태로 표현되며 수행시간이 빠르다.
- 고급 언어에 해당한다.
15. 새로이 반입된 프로그램을 주기억장치 내의 어느 곳에 둘 것인가를 결정하는 전략을 무엇이라고 하는가?
- Fetch 전략
- Replacement 전략
- Placement 전략
- Compaction 전략
16. 시스템의 성능평가기준과 가장 거리가 먼 것은?
- 신뢰도
- 반환 시간
- 비용
- 처리 능력
17. 어셈블리 언어를 두 개의 Pass로 구성하는 주된 이유로 가장 적절한 것은?
- 한 개의 Pass만을 사용하는 경우는 프로그램의 크기가 증가하여 유지 보수가 어려움
- 한 개의 Pass만을 사용하는 경우는 프로그램의 크기가 증가하여 처리 속도가 감소함
- 한 개의 Pass만을 사용하는 경우는 기호를 모두 정의한 뒤에 해당 기호를 사용해야 함
- Pass1과 Pass2를 사용하는 경우는 프로그램이 작아서 경제적임
18. 언어 번역기에 의하여 생성되는 최종 실행 프로그램이 보다 작은 기억 장소를 사용하여 보다 빠르게 작업을 처리할 수 있도록, 주어진 환경에서 최상의 명령어 코드를 사용하여 작업을 수행할 수 있도록 하는 것을 무엇이라 하는가?
- Code Integration
- Code Optimization
- Code Generation
- Code Initialization
19. 프로세스가 일정 시간 동안 자주 참조하는 페이지들의 집합을 무엇이라고 하는가?
- Locality
- Thrashing
- Paging
- Working Set
20. 컴퓨터 언어로 작성된 프로그램이 번역되어 실행되는 과정이 바르게 나열된 것은?
- loader → linker → compiler
- compiler → loader → linker
- linker → assembler → loader
- compiler → linker → loader
2과목: 전자계산기구조
21. 보조기억장치에 저장되어 있는 프로그램과 데이터 중에서 프로그램 수행에 필요한 부분을 주기억장치로 옮길 때 부족한 주기억장치의 용량을 확장하기 위해 보조기억장치의 일부를 마치 주기억장치의 일부로 사용하는 것은?
- cache memory
- virtual memory
- auxiliary memory
- associative memory
22. 데이터를 지우는 방식이 다른 기억소자는?
- EPROM
- EEPROM
- NOR 플래시
- NAND 플래시
23. 다음 parallel process 중 pipeline process와 가장 관계가 깊은 것은?
- SISD(Single Instruction, Single Data stream)
- MISD(Multiple Instruction stream, Single Data stream)
- SIMD(Single Instruction stream, Multiple Data stream)
- MIMD(Multiple Instruction stream, Multiple Data stream)
24. 다음과 같은 메모리 주소 22에 있는 명령어를 실행할 경우 누산기(AC)의 값은? (단, 명령의 내용 중 0은 직접주소방식을 나타내는 모드비트이며 현 AC의 값은 550 이다)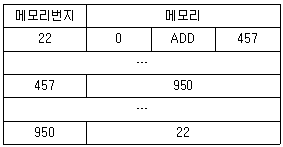
- 550
- 950
- 1407
- 1500
25. DMA(Direct Memory Access) 전송을 위하여 중앙처리장치가 DMA 제어기에 알려주어야 할 사항이 아닌 것은?
- 입출력 데이터를 저장하고 있는 기억장치의 시작 주소
- 레지스터 번호
- 데이터 전송 방향
- 데이터를 입출력 할 장치가 연결된 채널 번호
26. 하드와이어 방식의 제어장치에 관한 설명으로 가장 옳지 않은 것은?
- 제어신호의 생성과정에서 지연이 매우 작다.
- 구현되는 논리회로는 명령코드에 따라 매우 간단하다.
- 회로가 주소지정 모드에 따라 매우 복잡하다.
- 소프트웨어 없이 하드웨어만으로 설계된 제어장치이다.
27. 다음 중 직접 기억장치 접근 (DMA) 방식에 대한 설명으로 올바른 것은?
- 프로세서가 I/O 관리를 위해 직접 장치를 검사하는 방식이다.
- 프로세서가 직접 워드 전송을 위한 I/O 명령어를 수행한다.
- I/O를 위해 프로세서의 사이클을 스틸링(stealing)하여 메모리 버스에 접근한다.
- 블록단위의 전송보다 워드 단위의 전송에 더 효과적이다.
28. RS 플립플록에서 R=1, S=1 인 입력 조합의 경우를 방지하기 위하여 보완된 것은?
- D 플립플롭
- T 플립플롭
- JK 플립플롭
- FF 플립플롭
29. 다음 중 Associative 기억장치의 특징으로 옳은 것은?
- 일반적으로 DRAM보다 값이 싸다.
- 구조 및 동작이 간단하다.
- 명령어를 순서대로 기억시킨다.
- 저장된 정보에 대해서 주소보다 내용에 의해 검색한다.
30. 메모리 인터리빙을 사용하는 목적은?
- 기억용량 증대
- 입출력 장치의 증설
- 전력소모 감소
- 메모리 엑세스의 효율 증대
31. 아래와 같은 18비트 주소 형식을 갖는 주기억장치에서 접근 가능한 캐시메모리의 크기를 올바르게 계산한 결과는? (단, 3-way 세트 연관 사상을 고려하고, 태그가 저장되는 공간의 크기는 무시하고, 주소는 바이트 단위로 부여된다고 가정한다.)
- 16 KB
- 24 KB
- 32 KB
- 48 KB
32. 연산회로에서 반드시 필요한 신호로만 묶여 있는 것은?
- 덧셈신호, 보수신호, 끝자리올림신호
- 덧셈신호, 아랫자리올림신호, 곱셈신호
- 덧셈신호, 끝자리올림신호, 나눗셈신호
- 덧셈신호, 아랫자리올림신호, 지수신호
33. 다음 불 함수를 간소화한 결과로 가장 옳은 것은? (단, d()는 무관 조건임)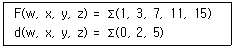

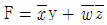
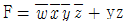
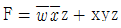

34. CISC(Complex Instruction Set Computer)와 RISC(Reduced Instruction Set Computer)에 대한 비교 설명으로 옳지 않은 것은?
- CISC는 명령어와 주소지정 방식을 보다 복잡하게 하여 풍부한 기능을 소유하도록 하고 RISC는 아주 간단한 명령들만 가지고 매우 빠르게 동작하도록 한다.
- CISC는 거의 모든 명령어가 레지스터를 대상으로 하며 메모리의 접근을 최소로 하고 RISC는 처리 속도를 증가시키기 위해서 독특한 형태로 다기능을 지원하는 메모리와 레지스터를 대상으로 한다.
- CISC는 명령어의 수가 수백 개에서 많게는 수천개로 매우 다양하고 RISC-명령어의 수가 CISC에 비해서 약 30%정도이며 명령어 형식도 최소한 줄였다.
- CISC는 데이터 경로가 메모리로부터 레지스터, ALU, 버스로 연결되는 등 다양하고 RISC-데이터 경로 사이클을 단일화하며 사이클 타임을 최소화한다.
35. 서로 다른 17개의 정보가 있을 때 이 중에서 하나를 선택하려면 최소 몇 개의 비트가 필요한가?
- 3
- 4
- 5
- 17
36. 주기억장치가 32K×12 용량이며, 캐시 메모리가 512×12용량이라고 하자. 한 블록의 크기가 8 워드라고 할 때 연관사상(associative mapping)을 한다면 주소의 태그(tag) 필드는 몇 bit인가?
- 9bit
- 10bit
- 11bit
- 12bit
37. 짝수 패리티 검출 방식을 알맞게 설명한 것은?
- 2진 정보 속에 있는 0의 개수가 패리티비트를 포함하여 짝수가 되도록 패리티 비트를 부가하는 방식
- 2진 정보 속에 있는 1의 개수가 패리티비트를 포함하여 짝수가 되도록 패리티 비트를 부가하는 방식
- 2진 정보 속에 있는 0의 개수가 패리티비트를 제외하고 짝수가 되도록 패리티 비트를 부가하는 방식
- 2진 정보 속에 있는 1의 개수가 패리티비트를 제외하고 짝수가 되도록 패리티 비트를 부가하는 방식
38. 프로그램 내의 모든 인스트럭션이 그들의 수행에 필요한 피연산자들이 모두 준비되었을 때 그 인스트럭션을 수행하는 것으로 데이터 추진(data driven) 방식이라 할 수 있는 것은?
- multiprocessor system
- vector processor
- pipeline processor
- data flow machine
39. 사이클 스틸과 인터럽트에 관한 설명으로 옳은 것은?
- 사이클 스틸은 주기억장치의 사이클 타임을 중앙처리장치로부터 DMA가 일시적으로 빼앗는 것으로 중앙처리장치는 주기억장치에 접근할 수 없다.
- 사이클 스틸은 중앙처리장치의 상태보존이 필요하다.
- 인터럽트는 중앙처리장치의 상태보존이 필요 없다.
- 인터럽트는 정전의 경우와는 관계없다.
40. 컴퓨터 시스템에 예기치 않는 일이 발생하였을 때, CPU가 처리하고 있던 일을 멈추고, 문제점을 신속히 처리한 후 하던 일을 다시 재귀하는 방식은?
- 인터페이스
- 제어장치
- 인터럽트
- 버퍼
3과목: 마이크로전자계산기
41. 컴퓨터의 명령어 사이클은 4가지 단계를 반복적으로 거치면서 동작한다. 다음 중 속하지 않는 단계는?
- Interrupt cycle
- Fetch cycle
- Branch cycle
- Execution cycle
42. 프로그램 크기가 가장 작은 주소 형식은?
- 0-주소형식
- 1-주소형식
- 2-주소형식
- 3-주소형식
43. 연계 편집 프로그램(linking editor)이 목적 프로그램을 입력으로 읽을 때 출력으로 생성하는 프로그램은?
- 로드 프로그램(load program)
- 유틸리티 프로그램(utility program)
- 매칭 프로그램(matching program)
- 서비스 프로그램(service program)
44. 마이크로프로세서에서 데이터가 저장된 또는 저장될 기억 장치의 장소를 지정하기 위해 사용하는 버스(bus)는?
- 레지스터 연결 버스
- 데이터 버스
- 주소 버스
- 제어 버스
45. 고수준 언어로 작성된 프로그램을 기계어로 번역하기 위한 프로그램은?
- 에디터
- 컴파일러
- 어셈블러
- 로더
46. CPU의 상태 플래그(status flag)에 관한 설명 중 틀린 것은?
- 보조캐리 플래그(auxiliary carry flag)는 BCD 연산에 사용된다.
- Z 플래그(zero flag)는 ALU의 연산 결과가 0인지 여부에 따라 셋트 된다.
- N 플래그(negative flag)는 ALU 연산 결과가 음수인지 여부에 따라 셋트 된다.
- 제일 왼쪽 비트에서 발생되는 올림수를 Cp, 왼쪽의 2번째 비트에서 발생되는 올림수를 Cs라 할 때 오버플로우(overflow) 발생 조건은 Cs+Cp로 주어지게 된다.
47. 포팅을 통해 리눅스 프로그램/유틸리티를 MS윈도에서 사용할 수 있도록 하는 프로그램은?
- cygwin
- perl
- JDK
- driver development kit
48. 입출력 프로세서와 CPU의 관계에 대한 설명으로 가장 옳은 것은?
- CPU와 입출력 프로세서는 무관하다.
- CPU는 입출력 프로세서에게 입출력 동작을 수행하도록 명령한 후 계속 관여한다.
- CPU는 입출력 프로세서에게 입출력 동작을 수행하도록 명령한 후 CPU는 다른 일을 수행한다.
- 입출력 프로세서는 CPU에게 입출력 동작을 수행하도록 명령한다.
49. CPU의 클록 주파수가 2.5MHz이고, 한 개의 명령 사이클이 3개의 머신 사이클로 이루어져 실행되며, 각 머신 사이클은 명령어 인출 및 해독 시 4개의 머신 스테이트가 필요하고 실행 시에는 각 6개씩의 머신 스테이트로 이루어진다면 한 개의 명령어를 실행하는데 걸리는 시간은?
- 0.4㎲
- 4㎲
- 25㎲
- 40㎲
50. 그림은 입출력 제어장치와 입출력 버스의 연결을 나타낸 것이다. 빈 블록 Ⓐ에 가장 적합한 내용은?
- Accumulator
- Status Register
- Shift Register
- Control Register
 의 Ⓐ는 Sense line을 통해 장치의 상태 정보를 받아 저장하는 위치이므로 Status Register가 가장 적합합니다.
의 Ⓐ는 Sense line을 통해 장치의 상태 정보를 받아 저장하는 위치이므로 Status Register가 가장 적합합니다.
51. 컴퓨터와 주변 장치 사이에서 데이터 전송시에 입출력 주기나 완료를 나타내는 2개의 제어 신호를 사용하여 데이터 입출력을 하는 방식은?
- strobe 방법
- polling 방법
- interrupt 방법
- handshaking 방법
52. 프로그램 입·출력 동작에 대한 설명으로 가장 옳지 않은 것은?
- 직접 I/O 또는 polled I/O 같은 데이터 전송이다.
- 마이크로프로세서에 의해 제어된다.
- 데이터 전송은 명령이나 입·출력 서브루틴에 의해 실행된다.
- 마이크로프로세서가 아닌 별도의 제어기에 의해 제어된다.
53. 하드디스크 또는 광학드라이브와의 데이터 전송을 목적으로 직렬연결을 이용한 컴퓨터 버스는?
- UART
- RLL
- IDE
- SATA
54. 일반적으로 DMA 장치가 가지는 3개의 레지스터가 아닌 것은?
- 주소 레지스터
- 워드 카운터 레지스터
- 제어 레지스터
- 인터럽트 레지스터
55. 데이터의 특정 부분을 제거(clear)하기 위해 사용되는 명령어는?
- AND
- OR
- Complement
- Shift
56. 대부분의 마이크로프로세서 CPU 소켓 인터페이스는 어떤 구조를 기반으로 하는가?
- PGA 구조
- DIP 구조
- BGA 구조
- LGA 구조
57. 다음 신호 중 양방향 신호는?
- 어드레스 신호
- 데이터 신호
- 인터럽트요청 신호
- 리셋 신호
58. 중앙처리장치의 하드웨어(hardware) 요소들을 기능별로 나눌 때 속하지 않는 기능은?
- 입력 기능
- 기억 기능
- 연산 기능
- 제어 기능
59. 파이프라인 프로세서의 설명 중 가장 적합한 것은?
- 다중 프로그래밍 시스템의 프로세서
- 제어 메모리가 분리된 프로세서
- 2개 이상의 명령어를 동시에 수행할 수 있는 프로세서
- 분산 기억장치 시스템의 프로세서
60. Recursive subroutine을 처리하는데 가장 적합한 자료 구조는?
- 큐(queue)
- 데크(dequeue)
- 환상 큐(circular queue)
- 스택(stack)
4과목: 논리회로
61. 다음 논리군 중에서 게이트 당 소모 전력(mW)이 가장 적은 것은?
- CMOS
- MOS
- TTL
- RTL
62. F(W, X, Y, Z) = 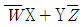 의 보수를 구하면?
의 보수를 구하면?

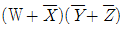
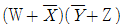
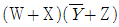
63. 8진 카운터를 구성하고자 할 경우 최소 몇 개의 JK 플립플롭이 필요한가?
- 3개
- 4개
- 8개
- 16개
64. T 플립플롭 3개를 종속 접속한 후 입력주파수 800Hz를 인가하면 출력주파수는?
- 8Hz
- 10Hz
- 80Hz
- 100Hz
65. 그림과 같은 논리 회로와 등가적으로 동작되는 스위치 회로는?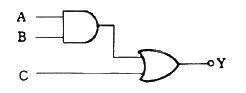
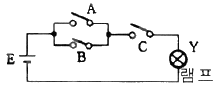
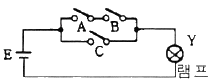
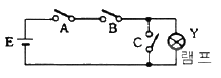
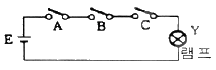
 가 정답입니다.
가 정답입니다.
66. 레지스터(register)의 기능은?
- 데이터(Data)를 일시 저장한다.
- 회로를 동기화 시킨다.
- 카운터의 대용으로 사용된다.
- 펄스(pulse) 발생기이다.
67. 16진수 AF63을 8진수로 나타내면?
- 135713
- 152734
- 147325
- 127543
68. 시프트 레지스터(Shift Register)를 만드는데 가장 적합한 플립플롭은?
- RS 플립플롭
- RST 플립플롭
- D 플립플롭
- T 플립플롭
69. 다음 그림은 D 플립플롭의 진리표이다. Q(t+1)의 상태는?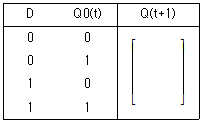
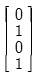

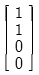
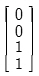
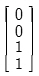
70. 다음 그림은 어떤 동작을 하는 회로인가?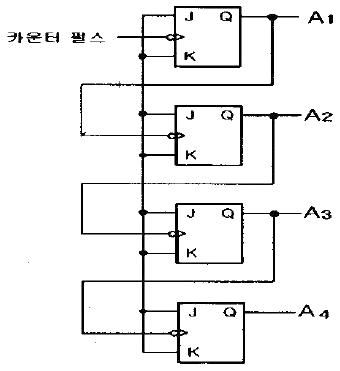
- 4비트 2진 리플 카운터
- 4비트 동기식 2진 카운터
- BCD 리플 카운터
- 시프트 레지스터
71. 다음 그림과 같은 논리회로의 명칭은?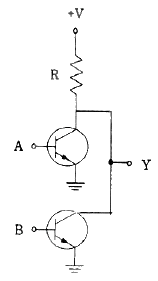
- AND
- NAND
- OR
- NOR
72. 다음 COUNTER는 연속된 Count pulse에 의해 어떠한 상태 변화를 나타내는가? (단, 초기상태 ABC = 000 가정)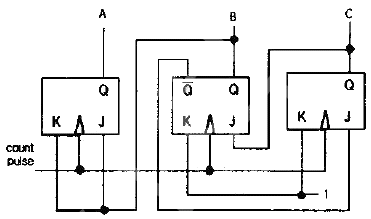
- 000→010→100→101→110→001→000
- 000→001→010→100→101→110→000
- 000→100→10→110→001→010→000
- 000→101→110→001→010→100→000
73. 짝수 패리티 비트의 해밍(hamming)코드로 0011011을 받았을 때 오류가 수정된 정확한 코드는?
- 0011001
- 0111011
- 0001011
- 0010001
74. 다음 논리함수를 최소화하면?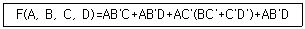
- F(A, B, C, D)=AC'+AB'+A'BC
- F(A, B, C, D)=AC'+AB'+A'BD+A'BC
- F(A, B, C, D)=AC'+AB'+A'BD+BC'D
- F(A, B, C, D)=AC'+AB'+A'BD+BD
75. 다음 회로에 대해 잘못 설명한 것은?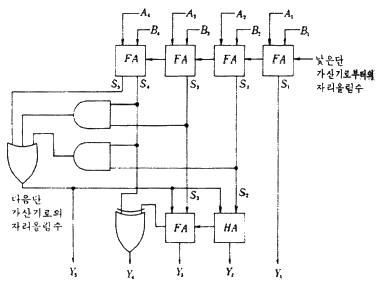
- 8421코드의 가산기이다.
- 가산을 행하여 그 합이 4가 넘으면 6을 더한다.
- 8421코드와 대응되는 10진수의 10이상의 코드는 의미가 없다.
- 8421코드와 대응되는 10진수의 10이상의 6개의 코드는 제외시킨다.
76. 직렬 또는 병렬방식 레지스터 전송에 대한 설명으로 가장 옳지 않은 것은?
- 직렬방식은 데이터를 전송할 때 많은 시간이 필요하다.
- 병렬방식은 하드웨어 규모가 간단하다.
- 직렬방식은 클록펄스에 의해 한번에 1bit씩 자리 이동한다.
- 병렬방식은 모든 bit의 데이터를 한번의 클록펄스에 모두 전송시킨다.
77. A1, B1은 첫 번째 A와 B의 입력 값이고, A2, B2는 두 번째 A와 B의 입력 값일 경우(A1,A2) => (A2,B2) 형식으로 표현한다. A+B를 계산하는 4비트 리플 캐리 가산기(4bit ripple carry adder)의 캐리 아웃(carry out)의 최대 지연시간을 측정하기 위해서는 입력 패턴을 어떻게 주어야 하는가?
- (0000, 0111) ⇒ (0000, 1000)
- (1010, 0111) ⇒ (1011, 0111)
- (1010, 0101) ⇒ (1011, 0101)
- (1111, 0000) ⇒ (1111, 1111)
78. 전가산기(Full Adder)의 구성은?
- 반가산기 2개, OR 게이트 1개
- 반가산기 2개, OR 게이트 2개
- 반가산기 2개, AND 게이트 1개
- 반가산기 2개, AND 게이트 2개
79. 4입력 디코더(decoder)는 최대 몇 개의 출력을 낼 수 있나?
- 4
- 8
- 16
- 256
80. 자기 보수 코드(self complementing code)가 아닌 것은?
- 5중 2 코드
- 2421 코드
- 3-초과 코드
- 51111 코드
5과목: 데이터통신
81. 프로토콜의 기본 구성 요소가 아닌 것은?
- entity
- syntax
- semantic
- timing
82. 신뢰성 있는 데이터 전송을 위해 사용되는 자동 반복 요구(Automatic Repeat reQuest) 방법이 아닌 것은?
- go-back-N
- control transport
- selective repeat
- stop-and-wait
83. 16상 위상변조의 변조속도가 1200baud인 경우 데이터 전송 속도(bps)는?
- 1200
- 2400
- 4800
- 9600
84. 다음 중 LAN에서 사용되는 채널할당 방식 중 요구할당 방식에 해당되는 것은?
- FDM
- CSMA/CD
- TDM
- Token Ring
85. Stop-and-wait ARQ 방식에서 수신측이 4번 프레임에 대해 NAK를 보내왔다. 이에 대한 송신측의 행위로 옳은 것은?
- 1, 2, 3, 4번 프레임을 재전송 한다.
- 현재의 윈도우 크기만큼을 모두 전송한 후 4번 프레임을 재전송 한다.
- 5번 프레임부터 모두 재전송 한다.
- 4번 프레임만 재전송 한다.
86. OSI-7 계층의 전송계층에서 사용되는 프로토콜은?
- FTP
- SMTP
- HTTP
- UDP
87. IEEE 802.4의 표준안 내용으로 맞는 것은?
- 토큰 버스 LAN
- 블루투스
- CSMA/CD LAN
- 무선 LAN
88. 10.0.0.0 네트워크 전체에서 마스크 255.240.0.0를 사용할 경우 유효한 서브넷 ID는?
- 10.1.16.9
- 10.16.0.0
- 10.27.32.0
- 10.0.1.32
89. 자동재전송요청(ARQ)기법 중 데이터 프레임을 연속적으로 전송해 나가다가 NAK를 수신하게 되면, 오류가 발생한 프레임 이후에 전송된 모든 데이터 프레임을 재전송하는 방식은?
- Selective-Repeat
- Stop-and-wait
- Go-back-N
- Turbo Code
90. 매체 접근 제어 방식 중 CSMA/CD와 토큰 패싱(Token Passing)에 대한 설명으로 틀린것은?
- CSMA/CD는 버스 또는 트리 토폴로지에서 가장 많이 사용되는 기법이다.
- 토큰 패싱은 토큰을 분실할 가능성이 있다.
- 토큰 패싱은 노드가 증가하면 성능이 좋아진다.
- CSMA/CD는 비경쟁 기법의 단점인 대기시간이 상당부분 제거될 수 있다.
91. 비 연결형(connectionless) 네트워크 프로토콜에 해당하는 것은?
- HTTP
- TCP
- IP
- FTP
92. 대역폭이 B(Hz), 신호대잡음비가 0인 채널을 사용하여 데이터를 전송하는 경우 채널용량(bps)은?
- 0
- B
- 2B
- 4B
93. 경로 지정 방식에서 각 노드에 도착하는 패킷을 자신을 제외한 다른 모든 것을 복사하여 전송하는 방식은?
- 고정 경로 지정
- 플러딩
- 임의 경로 지정
- 적응 경로 지정
94. HDLC에서 피기백킹(piggybacking) 기법을 통해 데이터에 대한 확인응답을 보낼 때 사용되는 프레임은?
- I-프레임
- S-프레임
- U-프레임
- A-프레임
95. 라우팅 프로토콜 중에서 최소홉수(hop)수를 기준으로 목적지까지의 최적경로를 결정하는 프로토콜은?
- RIP
- UDP
- EIGRP
- BGP
96. 아날로그 데이터를 디지털 신호로 변환하는 과정에 포함되지 않는 것은?
- encryption
- sampling
- quantization
- encoding
97. IPv4에서 IPv6로 천이하는데 사용되는 IETF에서 고안한 천이 전략 3가지에 해당하지 않는 것은?
- Dual Stack
- Tunneling
- Header Translation
- IP control
98. 다중화(Multiplexing)에 대한 설명으로 틀린 것은?
- 다중화란 효율적인 전송을 위하여 넓은 대역폭을 가진 하나의 전송링크를 통해 여러 신호를 동시에 실어 보내는 기술을 말한다.
- 동기식 시분할 다중화는 전송시간을 일정한 간격의 슬롯(time slot)으로 나누고, 이를 주기적으로 각 채널에 할당한다.
- 주파수 분할 다중화는 여러 신호를 전송매체의 서로 다른 주파수 대역을 이용하여 동시에 전송하는 기술을 말한다.
- 파장 분할 다중화는 각 채널별로 특정한 시간 슬롯이 할당되지 않고 전송할 데이터가 있는 채널만 시간 슬롯을 이용하여 데이터를 전송한다.
99. 다중접속방식에 해당하지 않는 것은?
- FDMA
- QDMA
- TDMA
- CDMA
100. TCP/IP 관련 프로토콜 중 하이퍼텍스트 전송을 위한 프로토콜은?
- HTTP
- SMTP
- SNMP
- Mailto
오답 노트
할당: 기억 장치 내 공간 확보 작업
링킹: 필요한 프로그램들을 결합하여 적재 모듈 생성
로딩: 실행 프로그램을 실제 기억 공간으로 옮기는 작업